hadoop3.x入门到精通-阶段三(HDFS源码..持续更新)
- ClientProtocol:ClientProtocol定义了客户端与NameNode之间的交互,这种接口方法有很多,客户端的文件系统的所有操作需要通过这个接口,同时,客户端需要先通过这个接口与NameNode协商读写文件等,在读写数据的过程中。
- 客户端数据节点协议(ClientDatanodeProtocol):客户端与数据节点之间的交互,主要用于客户端在调用时获取数据节点信息的界面定义方法,而实际的数据读写交互是讨论的后续流程界面。
- DatanodeProtocol: DataNode通过这个接口与NameNode通信,同时,NameNode通过接口中的方法返回值向DataNode发送命令。注意,这是唯一一种沟通NameNode和DataNode的方法,DataNode通过这个接口与NameNode注册,报告数据块的总数和额外数量的存储。同时,NameNode还通过该接口的方法返回值,命令DataNode执行复制、删除和恢复数据块的操作。
- InterDatanodeProtocol: 数据节点之间的通信,主要用于恢复数据块和同步存储在数据节点上的数据块拷贝。
- NameodeProtocol: SecondaryNamenode与NameNode之间的通信,因为 HA 机制已经引入,检查点操作不再由SecondaryNamenode执行,所以这个接口不需要详细解释。
- 其他接口包括与安全有关的RefreshAuthorizationPolicyProtocol、RefreshUserMappingsProtocol、HA相关接口,如HAServiceProtocol。
- 调用versionRequest()来握手
- 调用 registerDatanode()来将当前数据节点注册到namede
- 调用 blockReport()来报告在数据节点上存储的数据块
- 最后调用缓存报告()来报告数据节点缓存中的所有数据块
- Openhdfs文件: 第一个调用是 DistributedFileSystem. 基础调用是 ClientProtocol. 该文件的元数据信息 open()
- 从名节点获取数据节点的地址:名节点返回数据块的数据节点地址,然后根据数据块的位置将数据节点排列给客户端,然后客户端可以选择最后一个节点来创建连接并获取信息
- 数据节点创建连接,然后创建数据传输连接,当最后的包被接受一段时间后,客户端将一次调用ClientProtocol。 getBlockLocations()获取下一个数据节点读取的最佳距离
- 最后的数据传输将称为HDfsDataInputStream。 关闭() 关闭连接
- 创建文件:客户端将调用分布式文件系统。 创建()的下层执行是客户端协议。此操作被记录在编辑日志中,完成后返回HDfsDataOutputStream对象,它包含DFSOutputStream,实际可执行的操作是DFSOutputStream对象。
- 由于分布式文件系统,建立数据通道,仅创建一个空的文件夹,没有申请数据块,因此,DFSOutputStream首先调用ClientProtocol.addBlock()来在namede之前申请新的数据块,当namede返回数据块的位置信息时,客户端可以创建一个编写数据的通道
- 当写数据时,先写到数据流的缓冲区,然后通过切断数据来获取一个包。然后把它送到数据节点上,数据节点接受数据,然后验证数据的正确性。如果是这样,那该怎么办?这个包可以从数据流缓存中删除,当数据块满时呼叫addBlock() 应用新的数据块执行上述循环。
- 在所有文件被转移后,请调用ClientProtocol。 通知所有向文件提交的数据块的命名符号,从而完成整个数据写字操作
- 当数据节点启动时,它首先通过DatanodeProtocol..versionRequest()获取名称节点的版本
数目和存储信息等,然后Datanode将查看Namenode和Datanode的当前软件版本数目
比较当前的软件和版本数以确保它们是一致的。 - 在成功完成握手操作后,数据节通过数据节协议.register() 方法到 Namenode
Register.Nameode将在收到注册请求后决定当前的Datanode配置是否属于此集
组, 它们之间的版本数是否一致. - 成功注册后,数据节点需要报告所有本地存储的数据块和缓存的数据块
Nameode使用此信息重建内存中的数据块与数据节点之间的关联
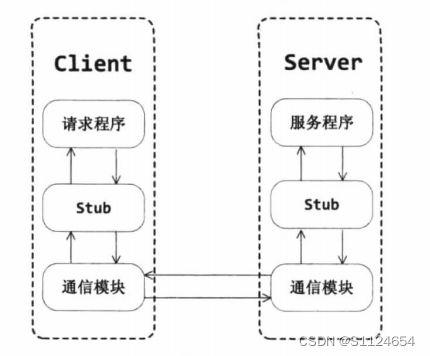
应关系。 - 通信模块:一种传输RPC请求和响应的网络通信模块,可以基于TCP协议,也可以基于
UDP协议可以同步或不同步。 - 客户端子程序: both servers and clients include subprograms.On the client, the subprogram performs smoothly
像本地程序一样,下层层序列调用请求和参数,并通过通信模块发送到服务
然后,子程序等待服务器的响应信息,重新排序响应信息并将其返回请求程序。 - 服务器端子程序:服务器端子程序将调用请求和参数发送到远程客户端
反向序列,根据调用信息触发相应的服务程序,然后返回服务程序的响应序列
列化并发回客户端。 - 请求程序:请求程序像调用本地方法一样调用客户端子程序,然后接收子程序
程序返回的响应信息 - 服务程序:服务器从子程序接收调用请求,执行相应的逻辑并返回执行结果。
最后更新:2022-07-01 05:39:01 手机定位技术交流文章
HDFS通信协议
Hadoop RPC 接口主要定义为 org.Apache.Hadoop.hdfs.server.protocol 和 org.Apache.Hadoop.hdfs.protocol 。这些主要包括以下接口:
ClientProtocol
上述五种方法是客户端必须调用来写文件的方法。
下列方法是例外
命名空间管理的相关方法
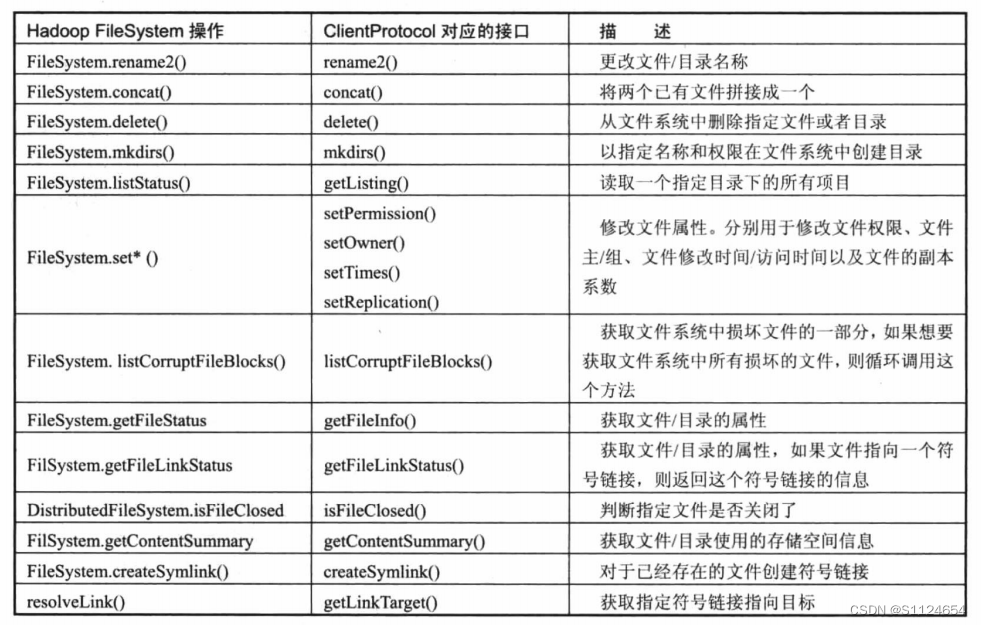
集群的安全模式方法
ClientDatanodeProtocol
客户端数据节点协议主要与客户端和数据节点通信,其方法相对简单,如下
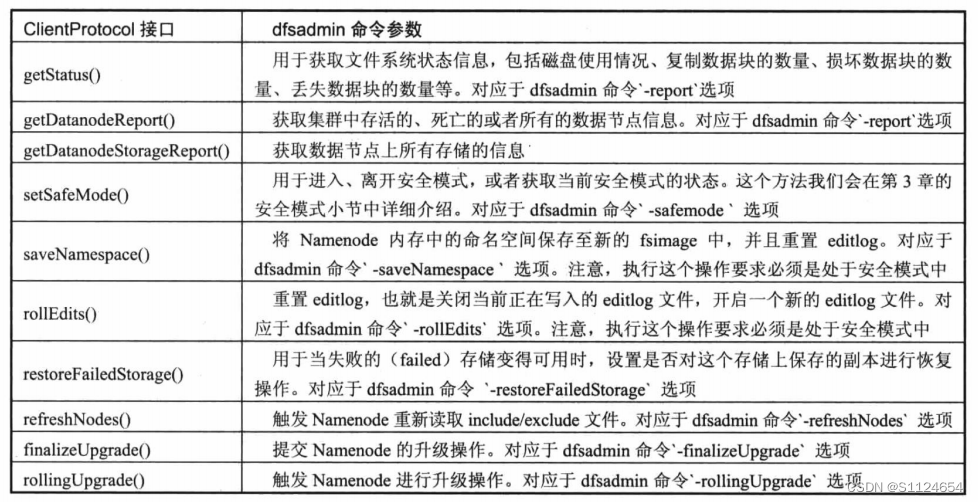
DatanodeProtocol
数据节点使用接口内存来发送握手、记录、心脏跳动、完整的或增量的数据报告,一个完整的启动操作由以下四个步骤组成
versionRequest()的主要功能是获取组信息、版本信息、数据块池信息等纳米诺德信息,然后数据节点比较其信息是否匹配,如果匹配,则成功握手
datanode调用 registerDatanode()向namenode报告自己的信息,然后调用 blockReport()报告自己的块信息
HDFS主要流程
HDFS读流程
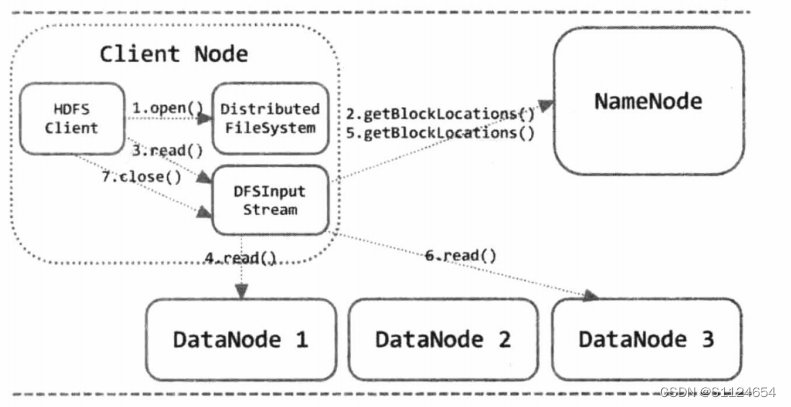
如果出现阅读错误,客户端通过DFSInputStream读取下一个节点,注意,在阅读文件时,除了数据块中所包含的信息外,还有数据校正信息,如果客户端读取的数据校正信息是错误的,客户端将通过Client Protocol.reportBadBlocks()报告到namenode错误块,使 namenode 删除相应的错误的副本,创建新的副本
HDFS客户端编写过程
介绍阅读过程后,让我们看一下客户写字的过程
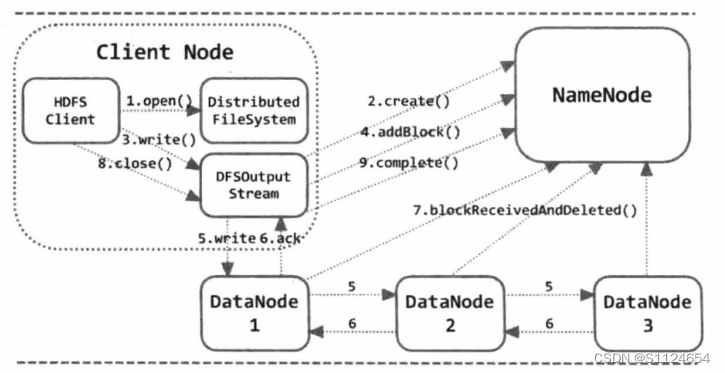
如果在编写过程中出现错误,客户端将切断连接并向namede报告创建新的连接
数据节点启动、心脏跳动和名称节点执行指令过程
介绍了客户过程,并介绍了数据节点和内门节点的交互过程
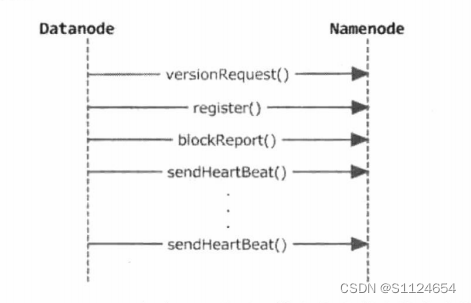
数据节启动后与 Namenode 的交互主要由三个部分组成: 1 握手; 2 登记: 3 报告
及缓存汇报。
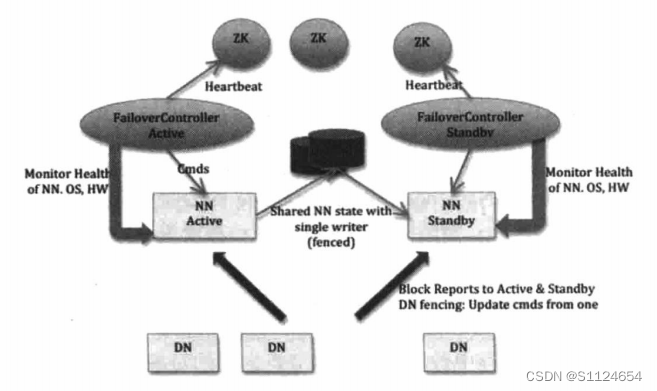
HA切换流程
HDFS的高可用性(HA)方案是为解决上述问题而创建的,在HA HDFS集群中同时运行两个 Namenodes,一个作为活动
(Active) Nameode,备份的备用nameode。 Active Nameode的名称空间
临时和待机 Namenode在实时同步,所以当ActiveNamenode失败并停止服务时,
StandbyNamenode可以立即切换到一个主动状态,而不影响HDFS集群的服务。
Hadoop RPC
RPC框架的结构主要由以下部分组成。
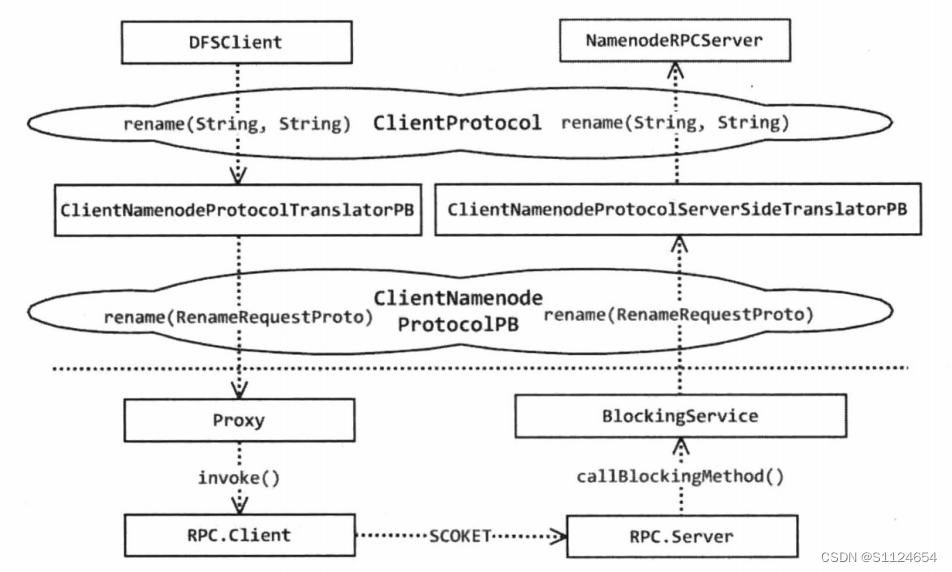
Hadoop RPC使用
图2-6给出了DFSC用户调用ClientProtocol的流程图。 再命名()方法的流程图
协议的定义部分。 ClientProtocol协议定义了与HDFS客户端和名称节点交互的所有方法,但
ClientProtocol协议中的方法参数不能通过网络传输,因此必须序列参数
HDFS还定义了ClientNamenodeProtocolPB协议。
所有的方法都由ClientProtocol定义,但参数都是用protobuf序列格式格式格式化的
例如, rename() 方法, ClientNamenodeProtocolPB rename(String,String) 方法在 ClientProtocol中
RenameRequestProto的两个参数被抽象到RenameRequestProto对象中, Rename()方法的签名变为
“RenameRequestProto”这个“RenameRequestProto”对象是通过一个原始缓冲器序列的对象
例如,一个可以通过网络传输的对象。
本文由 在线网速测试 整理编辑,转载请注明出处。

