【玩转Rabbitmq系列】01一文带你敲响Rabbitmq的大门
前言
兔子是什么
为什么我们应该使用消息中介
选择拉比特姆克的原因
Rabbitmq的四个核心概念
第五,六大讯息模型
总结
- 遵循AMQP协议
- 高可靠性,消息持久性可以保证消息的稳定性
- 集群部署简单,应用 Erlang 使得RabbitMQ集群部署变的超级简单
- 网络管理和监控为以后的操作提供了极大的便利
- 全功能, 支持消息持久性, 支持消息确认机制, 灵活任务发送
- 许多成功的应用程序,如阿里、Netbet和其他互联网巨头,已经被使用。
生产者(producer)
交换机(exchange)
队列(queue)
消费者(consumer)
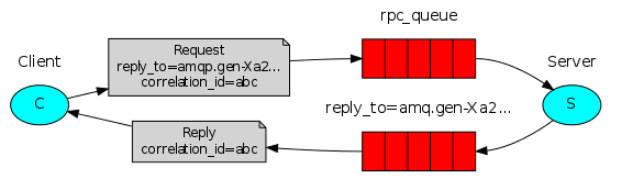
- 当客户端 ( P ) 启动时, 创建一个匿名 、 专有的回调队列 ( amqp ) 。
- **Client(P)**为RPC请求设置2个属性: ReplyTo(为设置回调队列名称); CorrelationId(为标记请求)
- 请求发送到rpc_queue queue
- RPC服务器端(S)监听rpc_queue队列中的请求,当请求到来时,RPC服务器端(S)会处理并且把带有结果的消息发送给客户端(P)。接收的队列就是replyTo设定的回调队列。
- 客户端(P)监听回调队列(amqp.gen-Xa2),当有消息时,检查correlationId属性,如果与request中匹配,即取出结果
最后更新:2022-07-31 14:02:10 手机定位技术交流文章

??个人主页:
学习方向:Java后端开发
??我的上一篇文章: 手把手带你搭建第一个SpringCloud项目(二)
如果我的文章对你有帮助,那么赞扬、收藏和信息是我最大的动力

[Rabbitmq系列] 文章直通到汽车
【玩转Rabbitmq系列】01:一文带你敲响Rabbitmq的大门
[Rabbitmq系列]02:Rabbitmq护士级安装说明书和基本消息模型在实践中
未完待续…
让我们正式打开今天的文本吧
文章目录
前言
在学习任何技术之前,我们都必须首先了解这种技术的使用,选择这种技术的原因,以及我们自己能得到什么样的帮助,只有当你学会的时候才会获得更多的动力。而今天,在我们正式开始学习Rabbitmq技术之前,让我们先了解Rabbitmq是什么,为什么我们选择它。
兔子是什么
Rabbitmq是基于AMQP(Advanced Message Queue Protocol)的可重用企业消息系统,用于软件之间的通信,是当今主流消息中介之一。

在这一点上,人们可能会问,Rabbitmq基本上是一个信息中介,它还有什么呢?
消息中介是利用高性能可靠的消息传输机制,以异步传输数据并集成基于数据通信的分布式系统。 在分布式环境中,可以通过提供消息队列模型和消息传输机制来扩展进程之间的通信。
应用程序间的一个组件,允许两个应用程序通过这个消息组件进行通信。
如下图所示,P和C之间的中间使用Rabbitmq实现消息传输和通信。
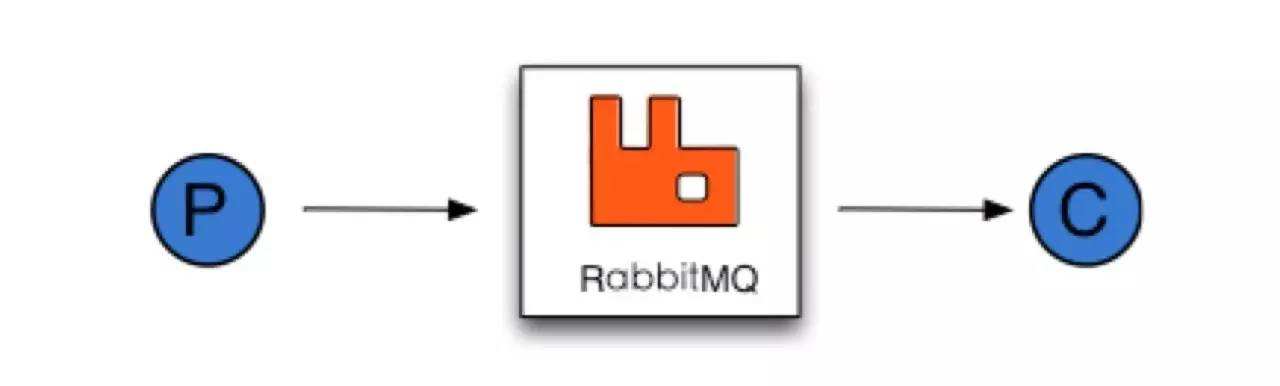
为什么我们应该使用消息中介
在现实世界中的场景和应用中,我们主要使用消息中介来解决以下三个问题:
1.应用解耦
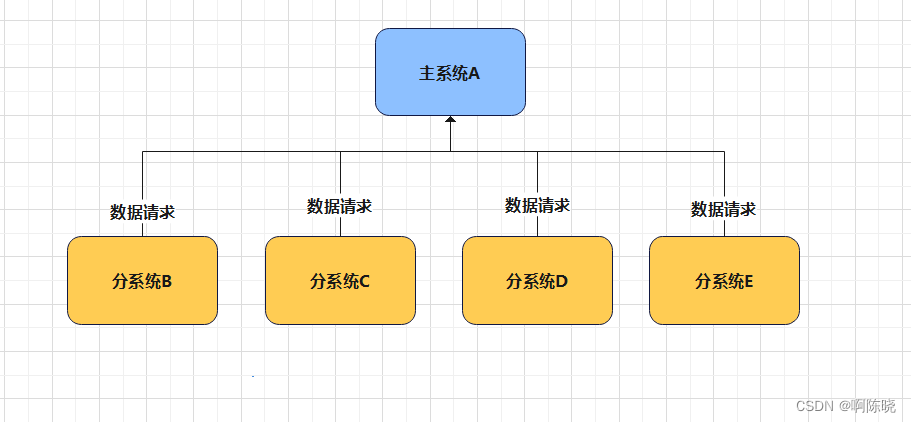
在当今的微服务架构中,一个应用程序由传统的应用程序巨人分成多个微服务,如果采用传统的消息传输方法,这个由多个系统组成的应用程序将导致系统间的高耦合,严重影响系统开发和维护效率。
例如,假设A有一个应用程序的核心数据,B、C、D、E必须在需要数据时向A提出请求,如果系统数目很小,A可以通过一个接口直接向每个系统传递数据。但是如果系统数量进一步增加,你必须把系统传递给数十万甚至几百万系统吗?如果其中一个系统瘫痪,造成异常,由于高度耦合的关系, 我们不该检查A中的商业逻辑 吗?这将严重影响我们实际开发中的开发效率和系统性能。
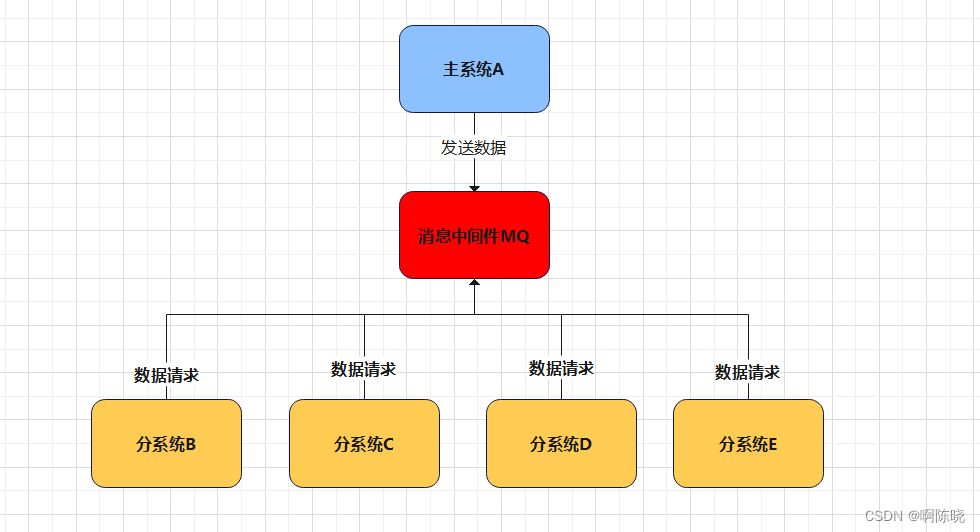
为了解决这个问题,我们引入了消息中间件MQ
如下图所示,我们介绍了A和其它系统中消息中心MQ,A将核心数据发送到消息中心。 其他系统通过MQ实现核心数据的访问,即使系统数目的变化没有影响A的操作逻辑,也可以解耦系统。
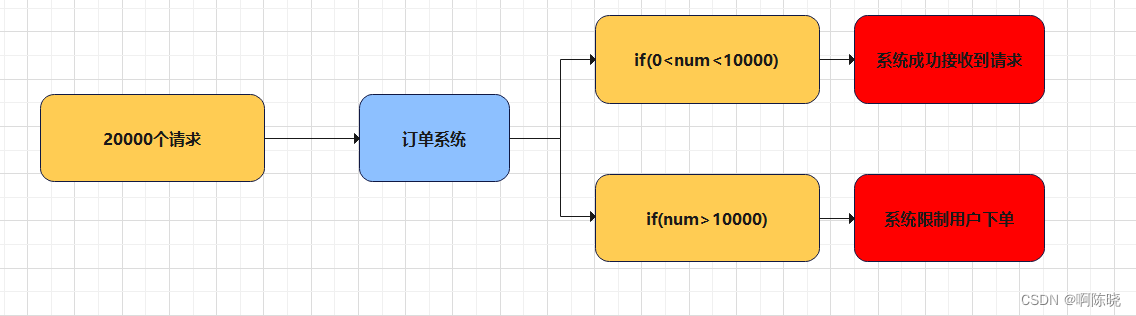
2.流量消峰
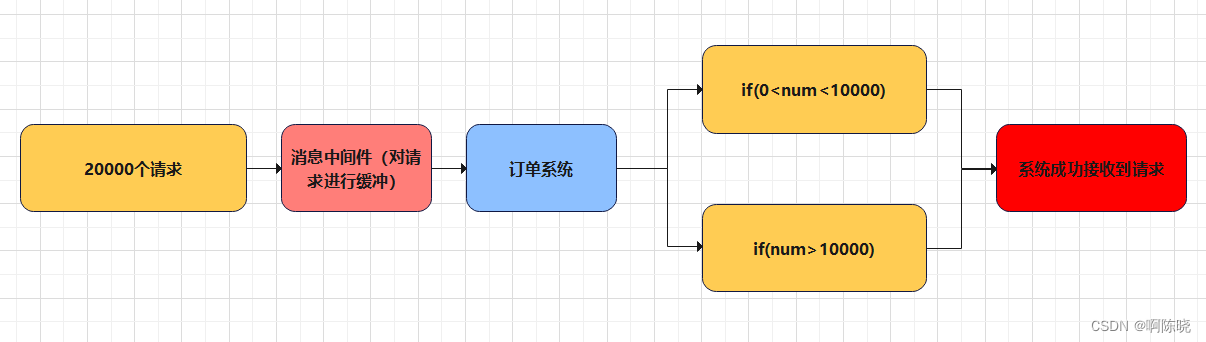
或者举个例子:如果一个订单系统在一段时间内处理最多10,00个订单,通常情况下,有足够的时间处理各种账单。但到了高峰时,订单的数量达到200件,此时,系统无法处理,只有限制超过10,00个订单的数量才能订购。这将严重影响系统可用性,降低用户体验。
我们还可以通过引入MQ来解决上述问题
如下图所示,我们加入消息中间件对20000个请求进行缓冲,把订单分散成一段时间进行处理。这样有一些用户可能会等待一小段时间,但是这远比系统不可用的体验感要好得多。
3.异步处理
在传统的业务逻辑中,业务之间的调用通常是顺序性,在这种情况下,即使业务之间的调用所消耗的时间很短,但是因为业务太多也会导致整个业务逻辑时间执行下来花费太多的时间。
例如,当我们在系统中启动请求时,我们需要经历下列业务链,如图所示:
因为业务链是顺序执行的,所以执行完成共花费20ms.但是在一些复杂的业务系统中,所需要付出的代价就远远不止20ms了,因此我们必须找出更好的方案来减少整个业务完成的时间。

对于上述问题,我们还可以通过引入中间消息来解决。
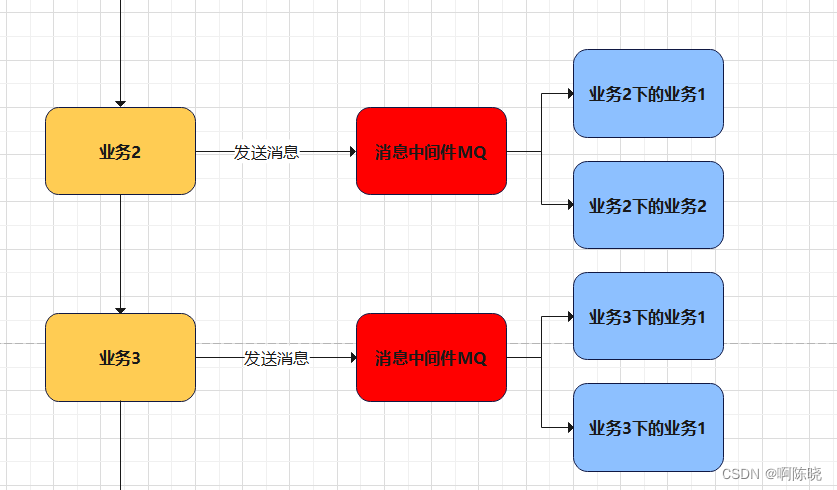
如下图所示,以业务2和业务3为例。让他们先把消息送到消息中心,在操作2和操作3下的其他操作则通过消息中间体获取相应的消息,让操作3不要等待操作2完全执行,然后再执行,操作间的异步处理通过消息中间体实现.这大大减少了操作执行时间,增加系统可用性。
选择拉比特姆克的原因
在当今市场, 有大量的信息中间件技术, 为什么我们选择Rabbitmq?
常见的消息中间件
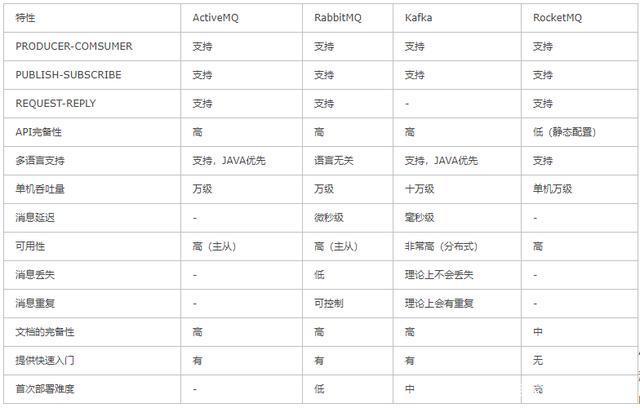
这是因为Rabbitmq具有以下特点:
基于上述特点,大多数在市场上的中小企业没有大量数据用于项目。 一个完全功能的Rabbitmq是一个很好的选择。
Rabbitmq的四个核心概念
简单点来说,Rabbitmq其实就像一个快递站点,不过他所传递的是消息而并非快递,接下来我们就以快递站点为例子引出Rabbitmq的四大核心概念。
在Rabbitmq中,有四个核心概念:
生产者是一个产生数据发送信息的程序
这个开关是兔MQ的一个非常重要的组成部分,一方面,它收到来自生产商的信息,另一方面,它将消息推到队列上。交换机必须知道如何处理它接收的讯息,是否将这些消息推到特定队列或多个队列,或丢弃消息,这必须由开关的类型决定
队列是RabbitMQ内部使用的数据结构,尽管信息流过RabbitMQ和应用程序,但它们只能存储在队列中。队列仅由主机的内存和磁盘限制,它基本上是一个巨大的信息缓冲器。许多制造商可以向队列发送消息,许多消费者可以尝试从队列中接收数据。这就是我们使用队列的方式
消费与接收具有相似的含义。消费者大多时候是一个等待接收消息的程序。请注意生产者,消费 者和消息中间件很多时候并不在同一机器上。同一个应用程序既可以是生产者又是可以是消费者。
简单来说,拿快递站点来比喻,生产者即是商家,商人(生产商)的特快邮件(信息),然后从快车站(换车站),快递站(交换机)必须知道快递(信息)是发往那条运行通道(队列),最后的表达式(消息)通过运行通道(栏)到达用户(消费者)手中。
第五,六大讯息模型
1、基本消息模型
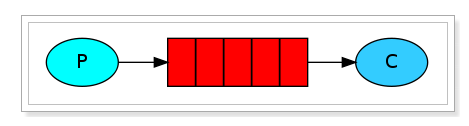
也就是说,一个消费端(C)从一个生产端(P)接收信息,信息被发送到**消息队列(图中的红色部分)。
工作消息模型
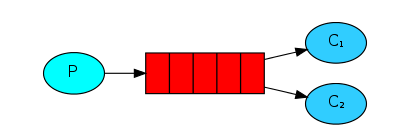
也就是说,两个消费者(C1)和(C2)在同一 ** 消息队列中消耗信息(图中的红色部分)**,但一个消息只能由一个消费者获得,C1和C2之间存在竞争关系。
3、Publish/subscribe模式
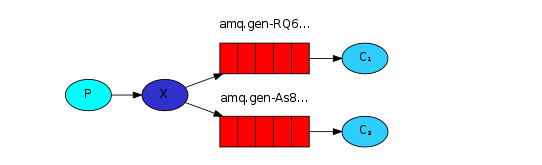
也就是说,生产者(P)向交换机(X)发送消息,交换机是Fanout(无线电类型),交换机发送消息到两个消息队列(图中的两个红色部分),然后C1和C2的消费者分别从相应的队列获取消息。
4.路由路由模型
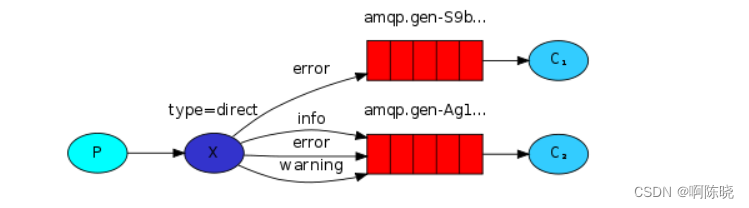
也就是说,制造商(P)用路由键发送消息给交换机(X),这里的交换机是直接的.交换机将消息中routing-key与队列中所带的routing-key进行匹配,即图中的error、info、warning,匹配成功地发送消息到相应的消息队列(图中的两个红色段),然后C1和C2的消费者分别从相应的队列获取消息。
主题匹配模式
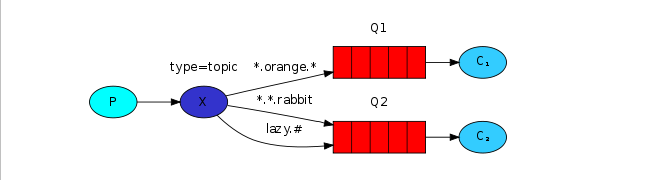
也就是说,制造商(P)用路由键发送消息给交换机(X),这里的交换器是主题(主题模式),交换机将消息中routing-key与队列中所带的通配符进行匹配,下面的图是*.orange.*,*.*.Rabbit, lazy.#,匹配成功地发送消息到相应的消息队列(图中的两个红色段),然后C1和C2的消费者分别从相应的队列获取消息。
通配符规则:
#:匹配0个或多个词
*:匹配1个词例子:
***.orange.*:****成功:**a.orange.b、ok.orange.ok1**失败:**a.orange.b.c 、orange.b
**azy.#:****成功:**azy、azy.a、azy.b.c**失败:**a.azy
6、RPC
总结
看这里,相信你已经掌握了Rabbitmq的初始理解,也许你还有一些没有特别理解的地方,不管怎样,在下面的一系列文章中,我将带你从简单的到复杂的Rabbitmq世界,从配置到实现一步步!
这就是我们今天的课的结局
谢谢你的阅读,我希望我的文章能带给你帮助!

先自我介绍一下,他高中毕业了13年,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。了解大多数年轻的Java工程师,想要升技能,经常需要找到自己的成长或向班上汇报。但对于培训机构来说,学费大约是人民币,着实压力不小。当你不在系统时,自我学习的效率很低,而且很持久。也很容易停止天花板技术。所以我为你收集了一个"java开发工具"初衷也很简单,这是一个想帮助自己学习的朋友,却不知道该从哪里学习。同时减少每个人的负担.添加下方名片,你可以得到完整的学习信息
本文由 在线网速测试 整理编辑,转载请注明出处。

