什么是插座?什么是文件描述符?你从一个非学生编码员那里得知的!
最后更新:2021-10-12 10:01:05 手机定位技术交流文章
什么是插座?什么是文件描述符?你从一个非学生编码员那里得知的!
絮叨
随着互联网业务的增长,市场上对程序员的需求增加,特别是对于并非少数的爪哇程序员的需求增加,而我是其中之一。 缺乏对计算机地板知识导致一些框架下层相关认识得不到理解。
我两天前就开始学习Redis, 正如我理解Redis为什么这么快, 一个奇怪的词出现在我面前, “Io manual ways again”, 所以我和大多数人一样, 有一些问题, 但我发现,要再次理解Linux的木质模型, 我必须要理解Linux的木质模型, 理解插座的连接, 理解文件的描述, 诸如此类。 在这一点上, 有人可能会认为我只能使用它, 我无法处理如此复杂的事情。 但我想说, 仅仅代表你做一个合格的程序员并不意味着你是一个出色的程序员。 所以我通过大博客的论坛, 我终于对这些奇怪的概念有了一些了解, 我将从一个非学生程序员的角度(上帝的觉悟脱身) 带你去了解套子和文件描述, 并了解Linux的其他木质模型。
首先,什么是插座?
在我们解释插座是什么之前,请考虑以下例子:如果我想联系我的女朋友,我先拨她的电话号码,然后通过收音机,然后我收到我的电话信号,然后按下电话,然后女朋友点击钥匙,电话连接完成。当连接成功时,你可以与你的女朋友交谈,她可以和你交谈。

如果计算机A希望通过网络与计算机B互动,计算机A必须有一个套套套,计算机B必须有一个套套。连接两个套套后,计算机A可以将接收数据发送到计算机B,计算机B可以将接收数据发送到计算机A。如果计算机A将数据发送到计算机B,计算机A通过SocketA的输出流从计算机B获得数据,计算机A从计算机B接收数据,计算机A使用输入流
二. 连接插座的程序
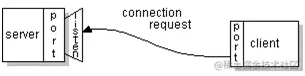
服务器(服务器)最初约束了80个端口(80个 HTTP超文本传输协议端口可供使用),服务器将等待客户(客户)向服务器提交连接请求。
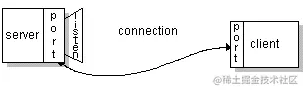
Clit 将通知服务器其端口号码和端口号, 使服务器在当地打开一个带有 Clit 端口号的端口, 并建立新的套接字, 以保证80 个端口套继续监听更多连接 。
这样一对配对就建立起来了 客户和服务可以发送和读取插座上的数据
三、TCP/IP和Socket之间的联系
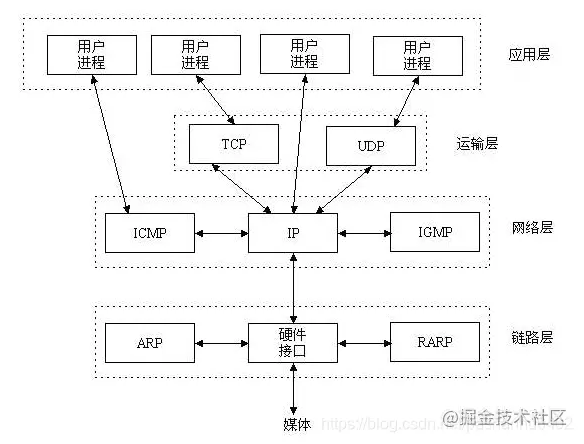
TCP/IP通称为《传输控制议定书/网络议定书》,是用来连接互联网连接装置的一套协议,一般类似于交通规则,TCP/IP协议是因特网间数据传输标准汇编。
这就是我要说的,索科特在哪里?
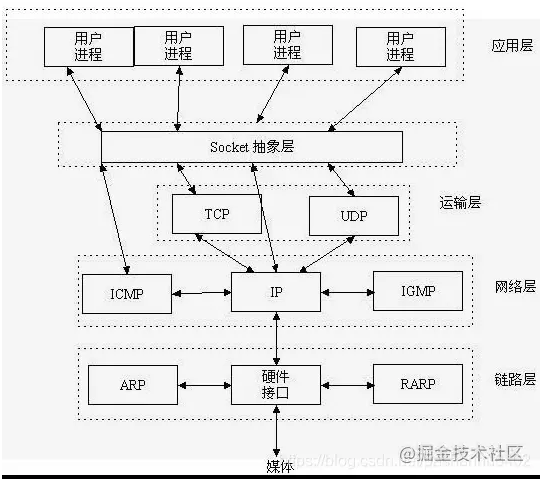
如图所示,Socket是连接TCP/IP社区的中间软件的抽象层,是接口的集合。TCP/IP是在操作系统中实施的,Socket是操作系统中将应用层核化的一系列界面。Socket覆盖TCP/IP,使用TCP/IP发送数据,调用Socket的输出流,使用TCP/IP接收数据,调用Socket的输入流,以及掌握TCP/IP和Socket之间的关系的时间。
四. Socket 读写缓存
计算机 A 现在计算机 A 和计算机 B 连接到 Socket? 不, Socket 先通过 Socket 的读写缓冲传输数据, 因此让我们通过 Socket 的读写缓冲。

首先,我们必须确定将数据,即用户状态数据传输到互联网的方法。我们必须将数据复制到内核,而内核能帮助我们发送数据。 因此,当计算机构造插座时,CPU会按照其本身的内在状态分配一对读写缓冲,其大小与数据数量无关。
计算机A希望将数据传送到计算机B,首先从计算机A向内核国输出缓冲区复制用户状态数据,然后通过因特网将输出数据传送到计算机B输入缓冲区,后者将数据传送到缓冲区,然后完成数据发送和接收。
建立数据缓冲区的范围有限,如果数据缓冲区不提供数据,用户国家此时要传送进一步数据,数据缓冲区空间将不够,将出现一些问题,如果计算机B接收数据,而没有从计算机A接收数据,输入缓冲将保持空档,造成问题。
Linux为这些挑战提供了五种解决办法,它们是Linux的五种主要的IO模式。
在理解IO模式之前,我们必须首先了解文件描述是什么。
究竟什么是文件说明?
文件描述(文件描述符)是操作系统为更有效地管理打开文件而生成的索引,用于识别打开文件。
Linux 操作系统中的每个进程都包括一个文件描述表,这是一个指针数组,而系统默认初始化数组的前三个位数。标准输入流(通常是键盘)的第0点,标准输出流(通常是显示器)的第1点,标准输出流(通常是显示器)的第2点,标准错误流(通常是显示器)的第2点。
现在,如果进程只有一个打开的文件, hello. txt, 文档描述表中第三个位置指的是此. txt 的指针。 如果此进程设置了一个投图板, 文档描述表下面的第四位指的是这个套接字的指针, 因为 Linux 中的所有文件都是文件, 而套接字也是文档。 我们谈论的文档描述符是此数组的下标, 因此, 在过程中, 文档描述符是此数组的下标 。
这是不言自明的:从前文可以看出,在我们第80个港口建立一个毛毯同样也是一份文件,因此,该进程的文件说明表增加了1份,增加了1024倍,以表明一个过程应限于我们系统的最多1 024份文件。
IO复用
IO 重新使用的历史与多个过程的历史一样长。 Linux 已经拥有了很长时间 。select后来,一个系统功能得到落实,使1 024个连接能够在单一程序内维持。poll系统调用,poll一系列强化措施解决了1 024个连接的制约因素,并允许维持数量无限的连接。然而...select和poll问题在于它们必须循环确定连接是否已经发生。 如果服务器有100w连接, 则在任何一个时间只将一个连接传送到服务器 。select/poll需要100个周期,只有一个周期是成功的;其余99w999个周期是无效的,浪费了CPU的时间资源。
直到Linux 核心6已经开始给一个新的了epoll该系统被要求维持无限数量的不四舍五入的连接,这是C10K问题的真正答案。 如今,所有高超语音的IO服务器都建在上面。epoll诸如Nginx、Node.Js、Erlang和Golnag.epoll技术。
80个港口主程序应产生最多1 024个沙克特[口袋实际上是一个连接],因此无论你产生多少次子处理,不再有连接主程序可以创建套接字,它只能使用选择模式将1024套接字连接到子程序。
此外,根据分解模型,这些插座可以在分解呼叫前使用,然后是分解显示器套接,即,分解(套接),当我们的过程被阻断时,分解会继续移动,当找到一个插座的数据时,它会通知过程,然后过程会发出一个系统呼叫,然后过程会发送一个读取系统来读取数据。
彩票与分辨没有根本的不同,只是他没有限制最大连接次数,因为他被锁在一个链桌内。如果它在一个过程内保持100w连接,那么绕着彩票走需要很长时间。然后,它会通知这个过程有一个插座,而这个过程经过100w插座也需要很长的时间。
民意测验和民意测验相似,因为它们并不限制连接次数,但民意测验模式不需要绕圈,因此当插座有数据时,它会立即通知过程,然后过程直接进入插座。
如果你把上面的线条看作是单向过程, 那么就是这条线来管理上面的吊坠, 每个插座都是一个请求, 所以木卫一的再利用可以处理许多请求。
1、Blocking IO
Linux 中的所有插座默认是全局的,典型的读取程序可能如下:
第一阶段一般是等待从网络获得数据,在全部数据准备就绪后,将数据转移到内核的缓冲区。
然后在第二阶段将数据从内核缓冲区复制到应用缓冲区。
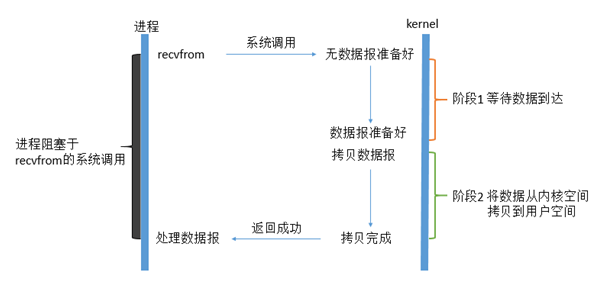
当用户进程调用系统后, 内核开始IO的第一阶段: 数据准备。 对于网络 i, 许多次的数据没有在开始时出现( 例如, 尚未收到完整的 UDP 软件包 ), 而当内核等待足够数据到达时 。 而对于用户进程, 整个过程被阻断 。 当内核等待数据准备好时, 它会将数据从内核复制到用户进程 。
因此,国际O的布局布局特征是,国际O执行的两个阶段都受阻。
2、非阻塞式I/O
在 Linux 上, 您可以通过配置套接字使它中午阻塞。 下面是阅读非全球套接字时的操作方式 :
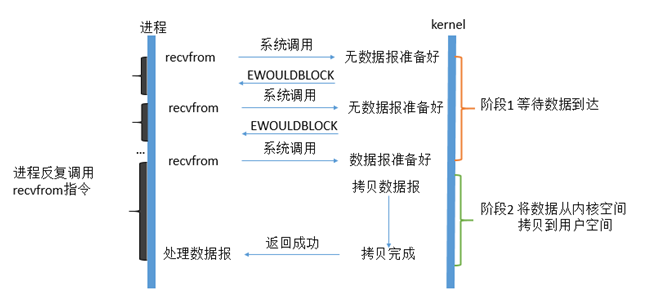
如图所示,如果当用户进程提交区域操作时, Kernel 中的数据无法提供, 它将不是一个黑色用户程序, 而是会立即返回错误。 从用户程序的角度来看, 它无需等待即可启动区域操作并立即收到结果。 当用户程序意识到 Kernel 中的数据尚未准备就绪时, 用户程序就会变成错误, 这样它就可以再次发送读操作 。 一旦 Kernel 中的数据已经准备就绪, 用户程序系统再次调用, 数据就会被传输到用户的内存并返回 。
因此,用户过程的第一阶段没有停滞不前,需要不断进行主动询问,以确定内核数据是否已经准备就绪;不过,第二阶段仍然受阻。
IO多路复用
“ IO manxing” 这个词听起来可能有点奇怪, 但是如果我说“ 教派, 民调 ”, 我大概会理解。 这种 IO 技术在某些地方也被称为“ 事件性研究 IO ” 。 众所周知, 选择/ 投放的好处是, 单个程序可以同时处理具有多个网络连接的 IO 。
IO再利用与不停止的IO基本原理相同,但新的选择系统已经用来利用内核处理本程序本来会要求的审讯,似乎有一个比不停止的IO成本更高的系统,但可以通过支持多常规的IO提高效率。
它基于这样的理念,即选择/投放是一个持续质疑的漏斗,当插座有数据时通知用户程序。 它包含一个流程图 :
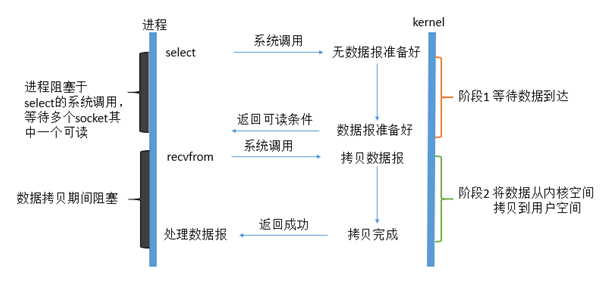
当用户进程调用了select,整个过程将被屏蔽,同时,内核将“观察”所有负责插座的插座,当插座中的任何数据准备就绪时,音量将返回。此时,用户程序被称为阅读操作,将数据从内核复制到用户程序。
虽然这里需要两个系统呼叫( 选择和校正), 但只有一个系统呼叫( recvfrom) 。 然而, 使用选择的好处是它可以同时管理许多连接 。 因此, 如果所处理的连接数量并不特别大, 使用列表/ poll 网络服务器可能并不总是比使用多威胁+ Global IO 网络服务器更可取, 而多威胁+ Global IO 网络服务器可能会更延迟 。
选择/投票的好处不是它能更快地处理个人连接,而是它能处理更多的连接。例如,波可以管理无限数量的连接。
事实上, IO 多重xing 模型中的每个套接字一般都设定为无阻塞, 但如上图所示, 整个用户的过程总是暗淡的。 它只是受制于函数区块, 而不是套接 IO 到 Block 的套接字 。
讲下我的理解。
多路复用首先,这是互联网编程的术语。多路.
多路:许多客户连接, 一条通经
复用:一个进程或线条可以处理所有上述连接。如果不重新使用,它必须同时为许多客户提供服务,并且需要多个线条或进程,这些线条或进程不能再利用,或线条可以处理所有上述连接。如果不再使用,它必须同时为许多客户提供服务,并且需要多个线条或进程,而这些线条或进程不能再利用。
本文由 在线网速测试 整理编辑,转载请注明出处。

