如您所见,物理介质上的数据框首先由 NNIC (网络适配器) 读取,并刻入环缓冲装置的内缓冲带,然后由Softirq 激活..
- 查看:
- 见最大和当前的 eth0 网页卡环缓冲设置 。
- 解决方案: 增加 Webcaeth0 硬件接收和传输缓存的大小 。
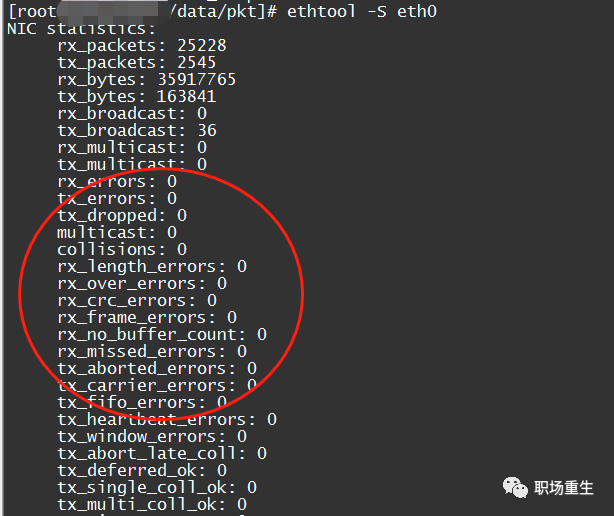
- 查看网卡丢包统计:
ethtool -S eth0 - 查看网卡配置状态:
ethtool eth0 - 重新自协商:
ethtool -r eth0; - 如不支持上游自行协商,可规定下列港口速度:
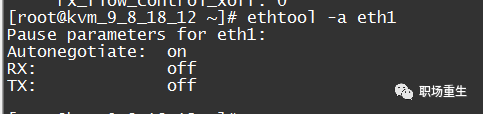
- 查看流控统计:
- 查看网络流控配置:
ethtool -a eth1 - 解答: 禁用网卡流程控制 。
- 抓取完成后, tcpdump 可以进入混合模式, 捕捉匹配的信件, 然后检查 Mac 地址 。
- 源头检查 arp 表格或抓取( 上一个跳跃器), 看看交付的 Mac 地址是否与下一个跳跃端的 Mac 地址对应 。
- 在发送软件包以启动再学习(这可能影响其他提交材料、造成延误和需要谨慎)之前,先刷新正本表格。
- 在源头,您可以手动设置右静态简表条目;
- RX错误:总接收错误数,例如过长框架错误、环缓冲溢出错误、 crc 检查错误、框架同步错误、 fifo 溢出和缺失 pkg 等。
- RX投放:表示数据集到达Ring Butffer,但由于记忆不足等系统性因素,在复制记忆程序时被丢弃。
- RX 溢出溢出: 表示自Ring Buffer (又名为司机 Quue) 的IO 广播比狗狗所能管理的IO 大, 而Ring Buffer 指的是IRQ 请求启动前的缓冲。 显然, 溢出率的上升表明,没有数据包Ring Buffer就抛弃了物理的网卡层, CPU甚至无法应付中断, 这是其中之一。
- RX 框架: 这个框架代表不匹配的框架 。
- 上述TX上升的原因,除其他外,包括由于CSMA/CD造成的传输中断。
- 更改网络卡上的 RSS 队列设置 :
- 让我们检查一下网络卡的中断设置 以确定是否有余额
cat /proc/interrupts - Netcardo队列和RPS设置根据CPU和因特网卡队列的数量进行调整。
- 0: 对任何互联网卡(包括回路卡上的地址)收到的关于该机器IP地址的快速请求作出答复,无论IP是否在接收卡上。
- 1: 仅回答其IP地址为接收卡的当地地址的rp查询。
- 2: 仅对预定IP地址(即接收卡的当地地址)的要求作出答复,而Rp要求的IP源地址必须与接收卡在同一节。
- 3: 如果ARP要求软件包的IP地址与其域名(范围)作为主机(主机)的本地地址发生对接,如果软件包是全球的或链接(链接),它不回应ARP对数据包的答复或ARP对数据包的答复。
- 查看arp状态:
cat /proc/net/stat/arp_cache完整表格 : - 见以下dmesg 消息(内核打印):
- 见当前arp表格的大小 :
ip n|wc -l - 此服务器目前不可用。 请检查是否指定 Lo 接口地址 。
- 无法关闭临时文件夹:%s。
ip r 显示表子子系统本地 grep这种降压包通常发生在几个IP场景上,多层次层配置失败,导致包丢失到适当的 ip; - 设置右接口 IP 地址; 例如,
ip a add 1.1.1.1 dev eth0 - 如果发现接口有地址并丢弃包件,当地路线表可能没有匹配项目,可在紧急情况下人工补充:
比如ip r add local本机ip地址dev eth0 table local; - 检查以检查路径是否正确( 可访问), 并指定触觉路径( 此设置显示在弹性卡片现场 ) 。
ip rule: - 查看系统统计信息:
- 0 - 不验证
- RFC3704:1 - RFC3704中所说的严格模式:每个收到的数据包的查询反向路径,如果数据包接入和出口反向路径不一致,则不通过。
- - RFC3704松散模式:每个收到数据包的查询反向路径,如果达不到接口,则不通过。
- 1: 关闭,只有未在 tcp 窗口中的首个包被标记为无效;
- 0: 任何不在 tcp 窗口中的包件都指定为无效 。
- 有几篇网络文章互相交流。
- (a) 始发端极具合作性,而血压和血压结构为出现这种疾病提供了便利;
- 增大系统网络内存:
- 系统回收内存:
- 检查界面 MTU 设置 。
ifconfig eth1/eth0,默认是1500; - 进行 MTU 检测, 然后设定接口的 MTU 值;
- 根据当前情景设定适当的 MTU 值;
- 设置适当的 tcp mss, 以便允许 TCP MTU 检测:
- 当打开客户端和服务时间戳( 默认打开)、 tw_reuse 和 tw_ recyll 时必须使用 。
- tw_reuse 只为客户工作,并在客户启动后一秒内恢复。
- 客户和服务器的回收工程在 3 。 在 5 *RTO, RTO 200ms - 120 取决于网络状况。 内联网比 tw_reuse 更快一些, 特别是公共网络移动比 tw_reuse 慢得多, 其好处是能够回收服务端的Time_ WAIts数量; 在服务端, 如果网络路径(b) tcp_ tw_ 区域, 造成时间戳破和其他损失问题的不确定性, 则网络路径(b) tcp_ tw_ 区域 。
- 如果内存可用, 请增加 tcp_ max_ tw_ bucket 的数量 :
- 已接受队列的大小 :
net.core.somaxconn - Listen 状态 : 当前等待服务呼叫接受进行三次听力积压的握手, 即当客户通过连接( ) 连接监听( ) 的服务端时, 它会继续在这个队列中进行, 直到服务被接受 (); Send- Q 表示最大的列表背对数值, 即上面提到的 Min (backlog, Somaxconn) 值 。
- 检查是否是应用程序限制, 直接倾听( 锁定, 积压) ;
- Linux内核是降压优化的(tcp_abort_on_overflow=1)。
- 哦,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,
- 应用程序设置和客户更新通知方面的问题;
- 提高tcp_max_syn_backlog 值。
- 减少 tcp_ synack_ retries 减少 tcp_ synack 键
- 应该启用 tcp_ syncookie 。
- 允许 tcp_bourt_on_overflow and tcp_bourt_on_overflowl1 将重置套件发送到 cliet, 信号显示握手过程和连接( 尚未在服务器端端形成) 将修改为 1 1, 这意味着当整个连接队列满时, 服务器将重置套件发送到 cliet ;
- 它被用来迅速恢复时间-世界旅行社的连接,但可能会在NAT范围内造成问题。
- 当几个客户通过NAT联网并与服务进行互动时,服务端看到同样的IP,这意味着这些客户实际上与服务端的IP相似,但由于有可能从服务端的角度对时间进行标记,从服务端的角度存在时间标记的危险,直接导致放弃时间标记数据包。
- 关掉延迟,把车开上快车道
- Linux通过简单关闭nagle算法而不是使用快轨实现不延缓。
- 打开 Quickack 选项, 包括一个 TCP UICKack 选项, 每个矩形后必须重新进入该选项 。
关闭Nagle算法, 降低小包件的延迟度 。
关闭延迟ack:
sysctl -w net.ipv4.tcp_no_delay_ack=1- 由于Probet不适用于实时音频和视频域,唯一的替代办法是直接删除它们或将RRT探测器缩短为2,作为BBRV2.5s一次,使用0.5xBDP传输。
- 如果没有具体要求,请使用可靠的立方算法。
- CPU负载(多核约束核配置)、网络负载(软中断优化、驱动线Netdev_max_backlog调整)、内存配置(有组织存储);
- 在峰值前增加缓冲缓存的大小 :
- 调整应用设计:
- UDP协议是一个互不相干和不可信的协议,适用于视频、音频、赌博和监视等情况,如果奇异信息丢失对程序状态没有影响的话。
- 如果服务器丢失了软件包, 请先检查系统负荷, 看看是否太高, 然后找到一种技术来减少负荷, 再检查一次, 看看它是否不见了 。
- 如果系统超载, UDP 投放软件包就没有有效的解决方案。 如果应用程序异常导致CPU、内存或IMO太高,请尽快找到应用程序并进行修正;如果资源不足,应尽早确认并迅速扩大监视范围。
- 对于通过调制系统和软件来接收或传输大量UDP包的系统,可以降低丢失包包的可能性。
- 应用程序以临时方式处理UDP包,在接收和接收信息之间没有过分的逻辑。
- (b) 检查缺失的包件;
- 查看统计:
- 由于IPCMP/UDP缺乏流动控制机制,它需要使用设计完善的交付和速度方法,其中考虑到底部宽幅大小、CPU负荷和网络带宽质量。
- 配置袜子缓冲器的大小 :
setsockopt(s,SOL_SOCKET,SO_SNDBUF, i(const char*)&nSendBuf,sizeof(int)); - 系统缓冲调整大小 :
- tcpdump工具
最后更新:2021-12-09 01:59:30 手机定位技术交流文章
找不到 Linux 的网络滴。 blog syxdevcode
物理介质上的数据框首先由NIC(网络适配器)接收,然后储存在环缓冲装置的内缓冲区,然后由干扰过程触发到Softirq,在那里,环缓冲的大小从一个卡设备到下一个卡设备不等。当网络数据包比内核处理(消费)更快到达(生产)时,环缓冲将很快满,新的数据集将丢弃。
 https://syxdevcode.github.io/2021/03/01/Linux%E4%B8%8B%E7%BD%91%E7%BB%9C%E4%B8%A2%E5%8C%85%E6%95%85%E9%9A%9C%E5%AE%9A%E4%BD%8D/
https://syxdevcode.github.io/2021/03/01/Linux%E4%B8%8B%E7%BD%91%E7%BB%9C%E4%B8%A2%E5%8C%85%E6%95%85%E9%9A%9C%E5%AE%9A%E4%BD%8D/
转载:
鸟眼观察云层网络倾弃场 和不对称
硬件网卡丢包
环缓冲的溢额
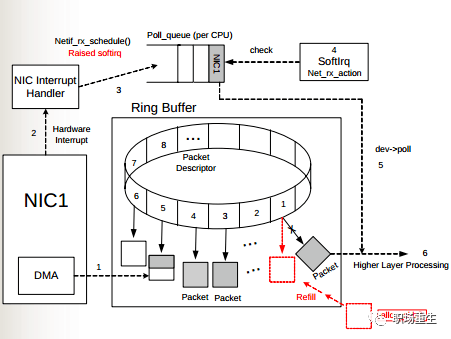
如图所示,物理介质上的数据框首先由NIC(网络适配器)接收,并写入设备内部缓冲区,然后由Softirq(由中断过程引发)使用,环缓冲的大小视网络卡设备的不同而不同。当基于网络的数据包比内核处理(消耗)更快到达(生产)时,环缓冲器很快会是完整和新鲜的数据集将被丢弃。
缺失的环缓冲包统计数据可通过ethtool 或/proc/net/dev, 以及贴有fifo标签的统计项目提供:
网卡端口协商丢包

观察与网络卡和上游网络设备协商的预计速度和模式。
解决方案:
网卡流控丢包

当 RX 缓冲器满载或其它网络卡资源受限时,打开传送到开关端的流量控制的制表符数为 Rx_ flow_ control_xon。当资源可用时,关闭流量控制的制表符数为 tx_ flow_ control_xoff。
报文mac地址丢包
大多数计算机网络卡以非复杂方式运作,这意味着他们只接受网络端口中标明自己数据的预定地址,如果提交的目的不是接口端端的 Mac 地址,则往往删除软件包。这往往是基于源的静态回转输入或动态学习正转输入没有及时更新的情况,但基于目的地的mac 地址已经改变(网卡已经改变),没有收到给源的任何通知(例如,更新报告已经丢失,中间开关是不正常的,等等)。
查看:
解决方案:
其他网卡异常丢包
这些异常现象并不常见, 但是如果它们不是上面全部列出的,
Netcard 的硬件版本 :
检查网络卡片芯片中的问题,如果安装的版本符合预期,以及ethtoto-i eth1:
eth1:

向制造商询问任何已知问题、新版本等等;
网线接触不良:
如果网卡统计中的 crc 误差计数增加,这很可能是由于网络联系不畅所致,您可以通知网络管道以下内容:
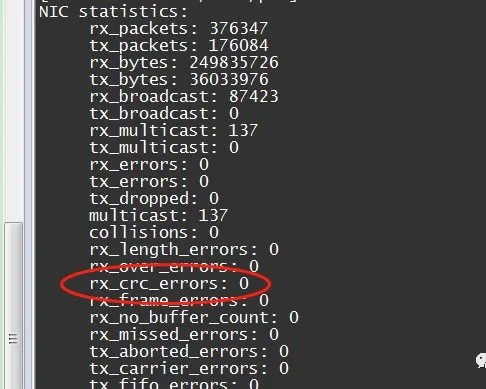
解决办法包括重新插入网络或以新的网络取代网络,确保插座符合港口标准等等;
报文长度丢包
网页卡有一系列接收准确信息的范围,一般范围为64-1518,电子邮件的长度通常涵盖这一范围:发送者端的正常情况得到填充或拍摄,偶尔出现异常情况,导致发送者信息中包裹不规则地下降。
查看:

解决方案:
1 更改接口的 MTU 设置以打开以太网框架;
2 发件人打开PATH MTU, 以便实现公平分割;
网卡滴数快速下降:

网卡驱动丢包
查看:ifconfig eth1/eth0等接口

驱动溢出丢包
Netdev_max_backlog 是在内核收到NIC(网络接口卡,通常称为网络适配器)的软件包之前的缓冲队列。 IP IP, TCP 。 Each CPU 核心有一个黑色队列, 与 Ring Buffer 一起, 当软件包以比内核处理速度更快的速度收到时, 当 CPU 的黑格队列增加时, 当设定的 Netdev_ max_ backlog 设置到达时, 将会被删除 。
查看:
通过查看/proc/net/softnet_stat可以确定是否发生了netdev backlog队列溢出:

从 CPU0 开始,每行显示每个CPU的状态;每列依次代表一个CPU的统计:第一列提供因处理过程中断而收到的包件总数;第二列显示因 Netdev_max_backlog 队列溢出而丢弃的包件总数。从以上输出可以看出,该服务器没有因 Netde 而减少的包件。
解决方案:
Netdev_max_backlog 的默认值为 100, 在高速链上, 可能会出现第二个计数不是零的情况, 而内核参数可以修改. net. I'm not sure you're talking about, core.Netdev_max_backlog 会处理下列问题:
单核负载高导致丢包
单核CPU破解率很高,导致申请无法接收和接收包件或接收和接收包件的速度缓慢,即使Netdev_max_backlog 队列被设定在一段时间内被删除、处理速度和接收离线卡的速度;
查看:mpstat -P ALL 1

(a) 100%的单核软中断,导致申请无法缓慢地接收和接收或接收包件;
解决方案:
查看:ethtool -x ethx;
调整:ethtool -X ethx xxxx;
调整:
- CPU 超过网卡队列数 :
查看网卡队列ethtool -x ethx;
(a) 协议仓库启动和配置RPS;
2) CPU低于破碎的卡片排队数量,可以关闭RPS并观察其效果:
echo 0 > /sys/class/net/<dev>/queues/rx-<n>/rps_cpus
四. Numa CPU 调整和调整网卡的位置,以提高内核处理性能,为应用程序收集软件包提供更多的CPU,并减少投放软件包的可能性。
见网卡上的Numa位置:
(b) 上述中断,以及在RPS设置中重新安装Numa CPU对遮罩至关重要。
五,尝试激活 分裂聚合物。
查看 :
调整:
网卡驱动袋处理简要概述:

内核协议栈丢包
以太网链路层丢包
相邻系统下降回数
放下 Arp_ignore 配置软件包 。
rp_ignore 参数的作用是规范当系统收到外部正转请求时是否返回正转。 rp_ignore 参数通常用于值为 0, 1, 2, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 38, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 38, 38, 38, 38, 38
查看:sysctl -a|grep arp_ignore
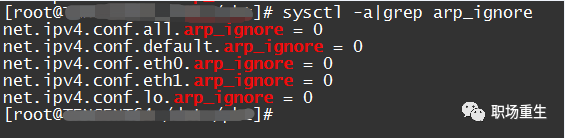
解决办法:根据实际情况设定适当的数值。
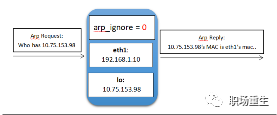

Arp_ filter 配置的拖放软件包
在多界面系统中(例如,对 tweak 云的弹性网页卡配置),这些界面可以响应回声请求,这意味着终端可以学习新的Mac地址,由于接收信件接口的Mac地址和Mac地址之间的差异,进一步传输可能导致包丢失,而ARp_过滤器主要用于适应现场。
查看:sysctl -a | grep arp_filter

解决方案:
(b) 根据当前场景调整相应的数值;默认情况下,这一过滤规则是封闭的,但不寻常的条件可以打开它。
0: 默认值,这意味着在回答简单查询时,对接口不进行校验。
1: 发出信号,表示在回复回复回复请求时,如果该接口与接收请求所使用的接口相同,即对接口进行核查,而这一差异被忽略;
arp表满导致丢包
例如,由于突然的 arp 表格元素数量超过了 Ark 的默认设置, 电文发送失败时生成部分 rp 元素, 导致发送失败, 软件包丢失 :
查看:

查看系统配额:
当有足够的内存时, gc_thresh3 值可以视为整张正数表的大小 。

溶液:根据实际最大正数调整正数表的大小(例如,进入额外机器的最大数量)。
Arp 请求使用缓存队列来填充空包 。
查看:
调整快取队列大小以满足客户需求 unres_qlen_ bytes
sysctl -a | grep unres_qlen_bytes

网络IP层丢包
接口 IP 地址配置的 Drop 软件包
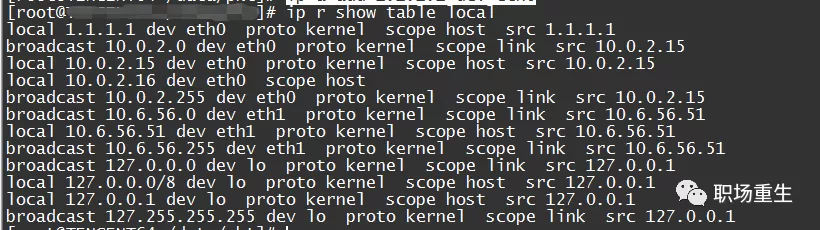
解决方案:
路由丢包
路由配置丢包
查看:

然后我们找到匹配的路径图

哦,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,不,
重新配置正确的路线作为变通办法。
反向路由过滤丢包
反向线路过滤是Linux的反向路线搜索,该搜索确定收到的源IP是否无障碍(丢失模式)、最佳路径(石墨模式),或者如果未经验证,则丢弃数据包,以保障IP地址免遭欺诈性袭击。
查看:
Rp_filter 有三个配置模型:
Rp_ filter 的当前政策配置 :
cat /proc/sys/net/ipv4/conf/eth0/rp_filter
如果设定为1,则必须确定东道方的网络环境和路线战略是否可能导致客户的一揽子计划未经逆向路线核查。
推理是,由于该方法在网络一级运作,如果客户可以连接到Ping服务器,则可以排除这一要素。
解决方案:
将 rp_ filter 更改为 0 或 2 :
防火墙丢包
客户确定了导致取消包裹的限制。
查看:
iptables -nvL |grep DROP
解决办法:修改防火墙规则;
连接跟踪导致丢包
连接跟踪表溢出丢包
内核输入使用 ip_contract 模块输入ipables 网络包的状态,并保存表格中的每个记录(本表格为内存)。/proc/net/ip_conntrack如果网络条件繁忙,例如高连通性、高连通性等,导致逐步占用这个不易填满且可以自行清理的可填表格空间,则表格记录将留在表格中,直到IP源发布 RST 软件包,但如果出现攻击、错误的网络配置、有问题的路由器/路由装置、有问题的网页卡等,则源IP发送了这个RST软件包,该软件包在表格中积累并积累到满满。 在任何一种情况下,当表格满时,软件包就满了,外部无法连接到服务器。 内核将给出以下错误信息:kernel: ip_conntrack: table full, dropping packet;
见最近的连接路径 :
cat /proc/sys/net/netfilter/nf_conntrack_max
解决方案:
ct 造成冲突损失,造成包件损失
另一个组织者(_A)cat /proc/net/stat/nf_conntrack你可以检查所有CT 异常的投放包。

溶液:内核补丁可用于修复或升级内核版本(混合补丁修改)。
UDP/TCP 落袋转移层
丢弃 tcp 连接连接连接音轨安全检查
包件损失:由于连接没有中断,因此没有合理的更新,但曾经出现过某些情况,如服务结束前包件异常或阴蒂(电文没有通过链接跟踪模块更新计算)。window范围,导致损失后续报告安全检查的包件;商定储存nf_conntrack_tcp_be_liberal来控制这个选项:
查看:
查看配置 :
查看log:
一般而言, Netfileer 模块不默认装入日志, 必须手动装入 。
当我们拿到包裹后,我们会通过系统
(b) 解决办法:根据对实际渔获量包的检查,可以试图关闭试验,不管投放物是否由机制触发。
分片重组丢包
情况总结:超时
查看:
解决方案:改变超时。
根据frash_high_thresh,超过特定级别的内存可能会触发系统安全检查丢弃包。
查看:
解决方案:调整大小
用分门别类的安全范围检查下装袋
查看:
解决方案: 将 ipg_ max_ dist 更改为 0, 并禁用此安全检查 。

在某些情况下,frag_max_dist 设置不适用:
与128的系统默认值128相比,巴克特冲突链过长。
查看:
火山灰因热补丁而变大了
由于系统缺陷,无法创建新的队列。
查看方法:
要看到下降, 请使用以下链接: dropwatch. com 。
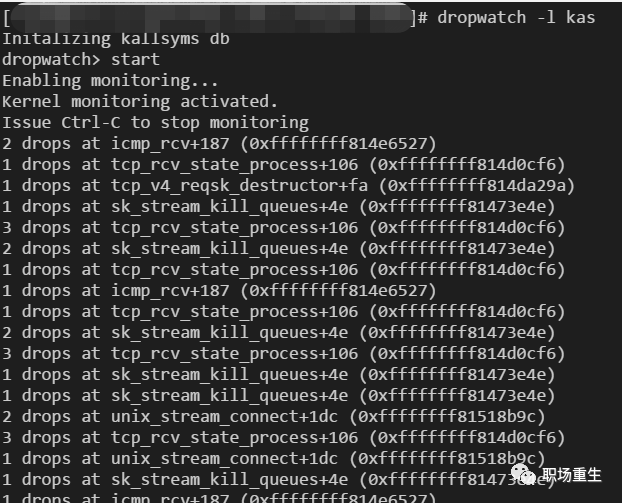
解决方案:
紧急情况下,可以用/proc/sys/vm/drop_caches为了释放虚拟记忆;
MTU丢包

查看:
解决方案:
tcp层丢包
时间离包装太远了
大量的TiMEWAIT假想是现成的,必须在一个连接时间短的高端TCP服务器上加以解决。 TCP服务器一旦请求由服务器处理,就自动关闭连接。TERMEWAIT中将有许多插座。如果客户的联手仍然很高,某些客户将表明目前缺乏连通性。
查看:
查看系统log :
查看系统配置:
解决方案:
时间戳异常丢包
当许多客户处于同一个NAT环境并访问服务器时,各种客户的时间安排可能不一致。 当服务器收到相同的NAT请求时,就会出现时间纠错,而后一数据包通常以客户提供SYN的形式被删除,但服务供应商对ACK没有反应。
检查:
解决方案:
不能启用通过NAT节点穿行的网络路线 。net.ipv4.tcp_tw_recycle;
Quan Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest Quest
原理:
(三手握手) tcp 状态机器

协议处理:
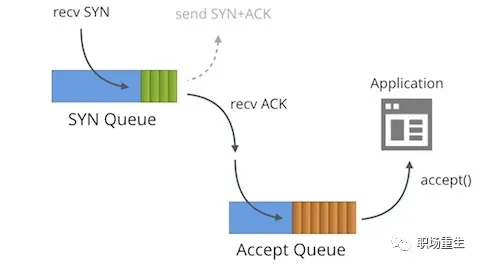
半连接队列( 同步队列) 就是一个例子 :
在三个“握手”协议中,服务器保留一个半连接队列,作为每个客户的 SYN 软件包,并有一个条目(服务所有人在收到SYN 软件包时创建了一个请求_sock 结构,存储在半连接队列中),这表明服务器已经收到SYN 软件包,并向客户发送确认其正在等待客户软件包确认的确认(第二个握手将发送SYN+ACK供确认)。这些条目的连接在服务器的 Syn_RECV 状态中,当服务器收到客户的确认软件包时,删除了条目,服务器进入了设置的ED状态。 团队被列为SYN 队列,最大(64,/ proc/sys/net/ipv4/tp_max_syn_max_syn_backlog),机器的tp_max_syn_backlog被配置在/proc/syls/net/ipv4/tcp_max_syn_backlog 下;
第一个是整个连接队列( 接受队列 ) :
服务器在第三次握手中收到 ACK 报告后, 它会进入一个被接受的新队列, 其默认值为 128 Somaxconn, 表示 ESTAB 最多 129 的连接正在等待接受 (), 而积压的值应该由插入列表中的第二个参数( 锁定、 内背) 确定, 可以通过我们的应用程序在监听中配置 ;
查看:
连接建立失败, 导致同步失败 :
它还受到被放弃的连接的影响。
解决办法:让它变得更大。tcp_max_syn_backlog
连接满丢包
-xxx times the listen queue of a socket overflowed
查看:
解决方案:
对不起,但包 被攻击 由合成食物。
目前,Linux默认再次释放SYN-ACK软件包5次,从1个开始,下一个再测试间隔是前一个间隔的两倍,再测试间隔的5个间隔是1个、2个、4个、8个、16个,总共31个,等待32个知道第5个时间太晚,所以T需要1个s + 2 + 2 + 4s + 8s + 8s + 16s + 32s = 63s
查看:
查看syslog:
kernel: [3649830.269068] TCP: Possible SYN flooding on port xxx. Sending cookies. Check SNMP counters.
解决方案:
PAWS机制丢包
理由:由于PAWS(防波数字保护)带宽高,TCP序列号可以在很短的时间内重复(循环/包装),可能导致在很短的时间内产生两个法律数据包,确认包和确认包的序列号相同,在同一TCP流中。
查看:
检查 Sysctl 是否启用了 tcp_ tw_ 回收和 tcp_ timestamp :
解决方案:
清除 tcp 时间戳选项,或者不打开NAT 环境的 tcp_tw_区域参数 。
TLP问题丢包
TLP主要旨在解决回落包再传输效率问题,TLP成功地防止了更长的RTO超时,从而提高了TCP的性能,如下所示:
TCP 尾部损失检验(TLP)是尾部损失检验(TLP)的缩写。
然而,在低时间延迟情况下(短链小包件),技术联络平台和延迟的ACK组合可能会造成低效率的再传输,导致客户对大量错误的再传输包的印象和反应延迟增加。
查看:
查看协议栈统计:
netstat -s |grep TCPLossProbes
查看系统配置:
sysctl -a | grep tcp_early_retrans

解决方案:
内存不足导致丢包
查看:
查看log:
dmesg|grep "out of memory"
查看系统配置:
解决方案:
基于TCP活动同时流动的系统参数调整,经常试图加倍或以其他方式增加,以测试缓解措施是否可实现;
TCP超时丢包
查看:
带上包,检查网络RTT:

用更多的工具检查当前的网络质量( hping, etc.) ;
解决方案:
TCP乱序丢包
TCP将暂时将这种情况描述为数据包的混乱,因为这是一个时间问题(可能数据包延迟到达),而放弃包将意味着重新传输。 当TCP意识到包件的混乱时,ACK立即意识到,ACK TER部分所含的TSEV值将记录目前接收者收到测序电文的时刻。 这将增加数据包中RRT样本的价值并进一步导致RTO的延伸。 这无疑对TCP是有用的,因为TCP有足够的时间来判断包件是否不正常或丢失以防止不必要的数据重新传输。
TCP紊乱和丢弃决定(使用重新排序更新算法) - 理论-网络过滤器、iptables/OpenVPN/TCP 授权书: - (- CSDN 博客_替换)
另一个组织者(_A)

解决办法:如果多通道传输状况或网络质量差,通过调整以下数值,系统向TCP的无序传输的误差率可以提高:

拥塞控制丢包
TCP算法随着互联网的出现而改变和发展。
Reno、 NewReno、 NewReno、 NewReno 和基于软件网络缺失的事件是被动的。 即使网络负荷高, 协议也不会自动降低自己的传输速度, 只要软件包没有拥堵, 协议不会自动降低自己的传输速度。 最初为出口转发的路由器比小, TCP很容易用于建立全球同步和低带宽利用率, 以及后来路由器制造商因硬件成本降低而不断增加 Boffer 和脂肪管道, 并且基于丢失的软件反馈协议继续使用路由器布弗, 同时增加带宽利用率的利用率, 也意味着在软件包被封后会增加网络的震动。 此外, 以高带宽和RRTs为主的长节流速度, 用于出口的最初路由路由器传输的最初路由器路由器传输的最初速度下降, 并且通过自动自动发送的节时序、 节路由机流生成的节流控制, 使得BCP的最大节流速度持续使用。
4. 内核首次使用了BBR Condensation Control Algorithm的初始版本,该版本比其他算法更健全,但在某些情况下存在缺陷(缺陷),以及BBR在实时音频和视频方面的问题,这些对立方体而言不够具有竞争力。
问题是,在BBR Probett阶段只发布了四个一揽子计划,而交付率的大幅度下降可能会在Caden造成延误和问题。
查看:
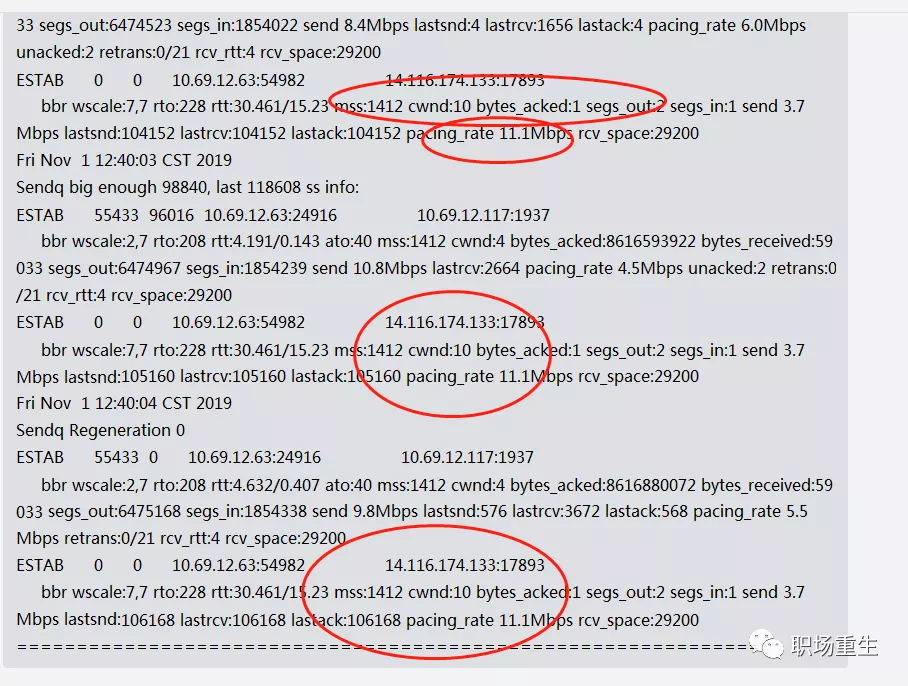
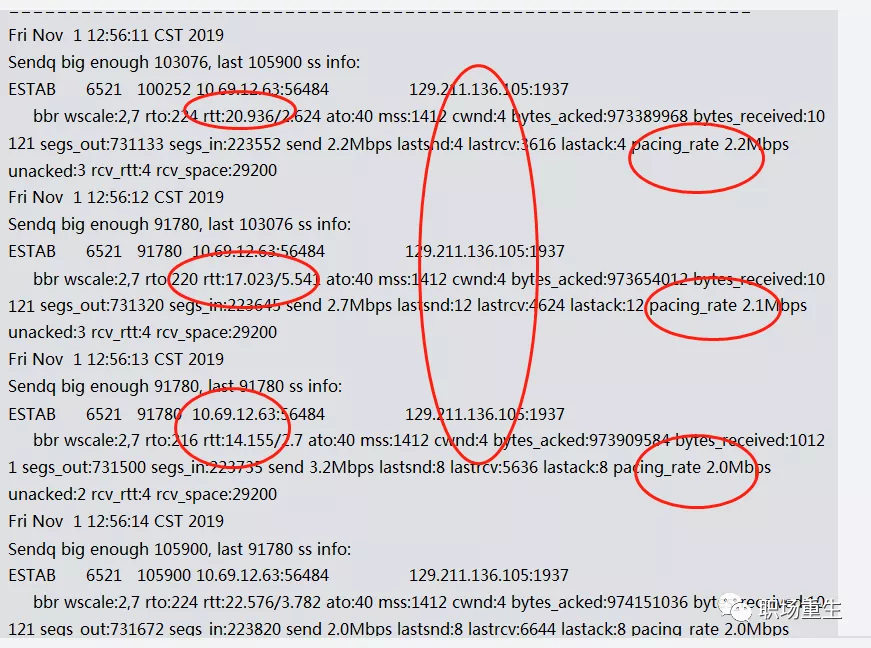
解决方案:
UDP层丢包
收发包失败丢包
看看净统计数据。
如果有连续缓冲错误/ 发送缓冲错误的数数;
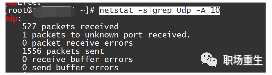
解决方案:
应用图层插件的拖放袋
投放袋将被发送到折叠夹缓存处 。
查看:
netstat -s|grep "packet receive errors"
解决方案:
具体大小调整原理:
没有任何设定值的缓冲区的面积是最佳的,因为根据没有设定值的缓冲区的情景适当情况,最佳规模会波动,最佳规模会波动,因为最佳规模会根据情况波动。
估计缓冲区的理由:在数据通信中,带宽长度系数(又称带宽延缓产物、带宽长度系数、带宽长度质量等)是指数据链的容量(每秒比特)以及进出通信的延迟度(单位)。 [1][2] 结果是以比特(或字节)计算的数据总量,相当于网络线上任何时刻的最大数据量,数据虽已发送,但尚未确认。
BDP=带宽乘以RRT
可以通过计算当前节点的带宽和统计平均时间,并将其与下列常见情况进行比较,来计算发展局或缓冲区的大小:

11. 管理活跃的TCP/IP网络、IPMP和IPIP隧道
投放软件包时, 请使用连接设置的 tcp 数 。
查看:
请见前面的 TCP 链接队列分析 。
解决方案:
指定数量相当的连接队列,在ACK接收到第三个握手后,加入一个称为接受的新队列,该队列的值默认为128索马克斯康,表明与最多129人的 ESTAB 连接正在等待接受 (),而积压的值应该由插件(in lockfd, intbacklog)中的第二个参数提供,该参数可以由我们的应用程序配置;
申请发送得太快,造成袋子掉落。
查看统计:
netstat -s|grep "send buffer errors"
解决方案:
附件:内核倾弃场一览表:

相关工具介绍
1. 人种观察工具
理由: 听 kfree_skb 函数或事件( 被丢弃 Web 消息时的功能), 并显示相关的调用堆叠; 如果您想知道 Linux 系统正在运行哪个功能, 请使用 dropwatch 工具, 该工具会监听系统滴落并打印投放软件包发生时的函数 :

tcpdump是下一个强大的Unix网络捕捉工具,用户可以拦截和显示TCP/IP和网络传送或接收的其他数据包,以便与计算机连接。
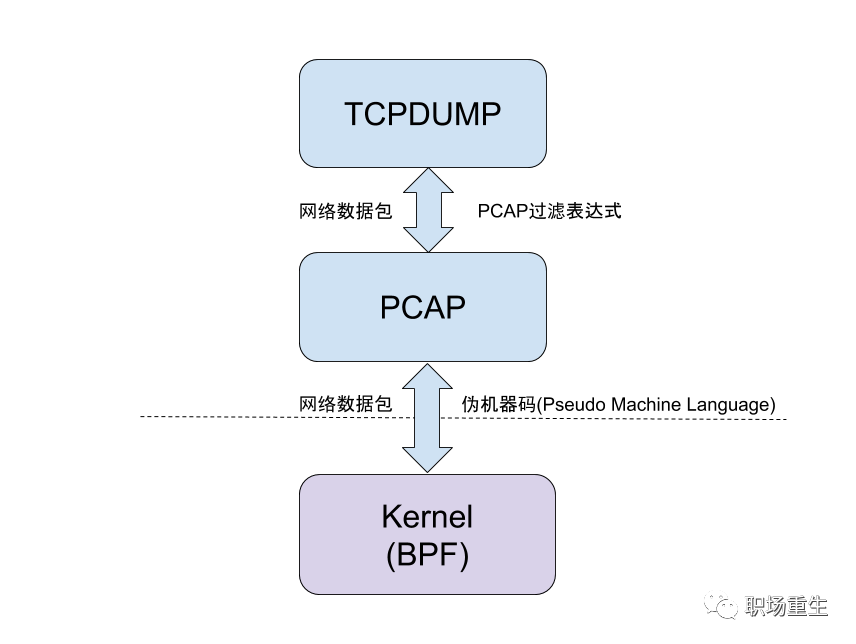
抓包命令参考:
Man page of TCPDUMP
数据包分析:
1. 使用有线卫星工具进行分析,参考:Wiresark数据包实地业务分析。
2. 可转换成CSV数据,用于使用Excel或shell分析个别现场报告。
在Linux上,可以用沙皇指挥线工具来检查:
tshark(1)
本文由 在线网速测试 整理编辑,转载请注明出处。

