Python爬虫编程1———爬虫简介_彩色的泡沫的博客-CSDN博客
- 要素:要素、网络汇码、数据提取和分析(一些数据经过仔细处理,因此并非所有数据都正确)
- 控制台:控制台(打印数据)
- 资料来源:资料来源(从互联网下载的文件)
- 网络工作(信息抓取)可处理大量页面查询。
最后更新:2022-01-01 04:51:08 手机定位技术交流文章
目录
一.通讯协议
1.端口
2.通讯协议
二.网络模型
一,HTTPS到底是什么?
二. SSL如何理解?
3. http请求和回应
四. HTTP 客户请求
五. HTTP定期请求的示例
6.请求方法
三.爬虫介绍
1.什么是爬虫?
2.为什么需要爬虫
公司获取数据的三种方法
四,Python作为爬行动物的优势。
5.爬虫的分类
四.重要概念
a. GET 和 a.POST 和 a.GET 和 a.POST 和 a.GET 和 a.POST 和 a.GET
2.URL组成部分
3. 用户代理用户代理用户
4.Referer
五.抓包工具
一.通讯协议
1.端口
为了传输数据,我们要采取多少步骤?
1.找到对方IP;
two.Data 被转移到另一方提供的申请中。 为了识别这些应用程序, 它们都是数字标记的。 为了便于参考, 它被称为港口 。
3. 确定通信规则。 该通信规则一般称为协议。
2.通讯协议
TCP/IP协议由国际组织界定,所谓的协议是指在计算机通信网络协议中两台计算机之间通信必须遵守的准则或规则,由国际组织界定,所谓的协议是指计算机通信网络中两台计算机之间通信必须遵守的准则或规则。
HTTP,通常称为超文本传输议定书(电信议定书),使用80号港口。
二.网络模型
osi模型
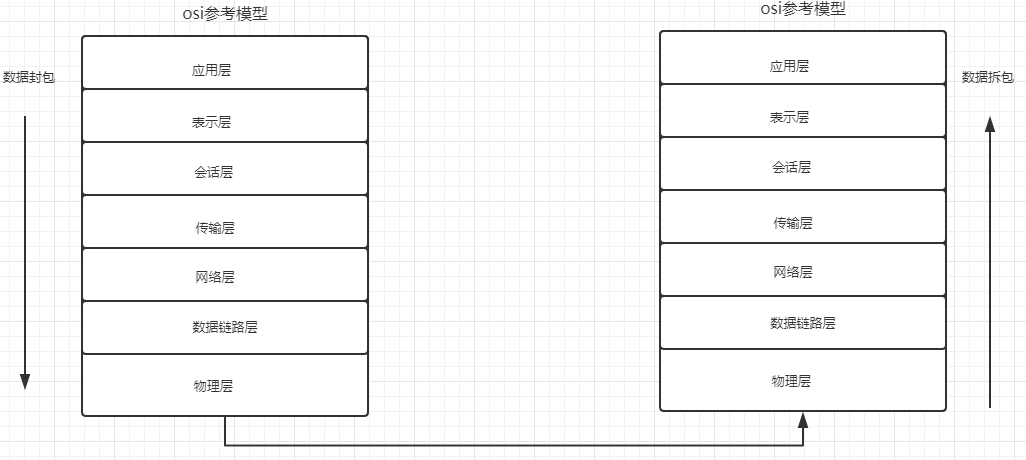
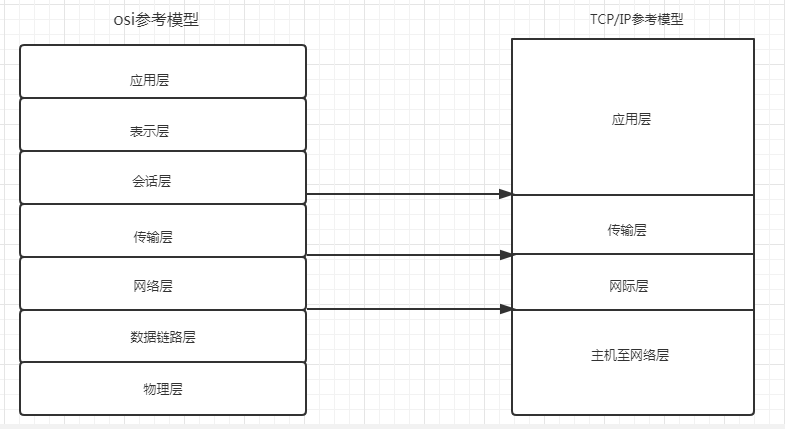
后来,更新了一个新的参考模型,即TCP/IP参考模型。
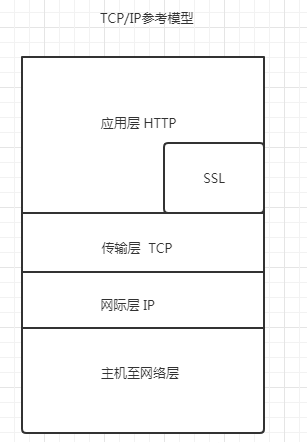
一,HTTPS到底是什么?
一. https = http + ssl;根据定义, https 将SSL 屏蔽添加到 http 上, 并且信息在 SSL 中加密 。
2 https, 安全 HTTP 频道, 基本 HTTP 安全版本。 这是 HTTP 的安全版本。 HTTP 的安全基础是 SSL 。
二. SSL如何理解?
SSL是一个协议,主要用于网络安全通信方法。
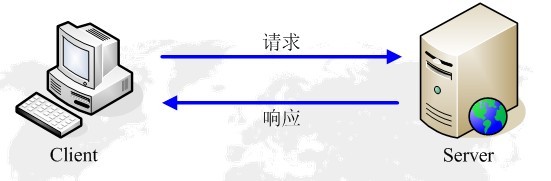
3. http请求和回应
客户要求和服务器答复是HTTP交换的两部分。
。 当用户在浏览器地址栏中输入 URL 并按下 返回 键时, 浏览器会将 HTTP 请求发送给 HTTP 服务器。 HTTP 请求会被分隔为“ get” 和“ post” 方法 。
当我们把以下的 URL 输入浏览器时 : https://ww.un.org/I don't know what you're talking about, baby. Com Time浏览器发送了一个请求 请求检索 https://ww.com.com/I don't know what you're talking about, baby.服务器将响应文件对象发送到浏览器。
浏览器检查了“ 答案” 中的 HTML, 并发现了更多的文件, 如图像文件、 CSS 文件 和 JS 文件 。 浏览器自动再次发送请求, 以获取图像、 CSS 文件 或 JS 文件 。
四. 在所有文档成功下载后,网页按照 HTML 语法结构完全显示。
四. HTTP 客户请求
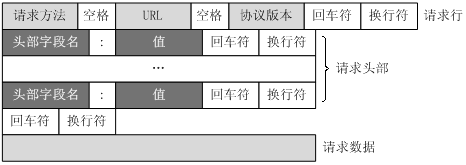
URL 只指定资源的位置, 但 HTTP 用于提交和访问资源。 客户将 HTTP 请求的信息传送到服务器, 包括以下格式 :
请求栏、请求页眉、空白栏和请求数据为四个要素,下表显示请求书的通常结构。
五. HTTP定期请求的示例
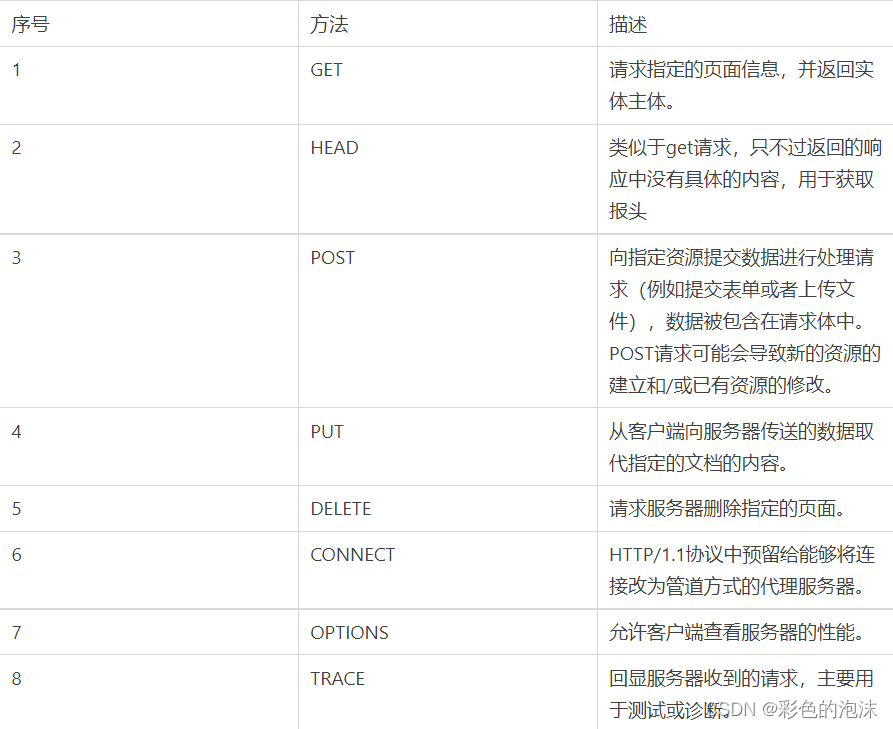
6.请求方法
根据HTTP标准,HTTP请求可采用几种请求方法。
HTTP 0. 9: 仅有最基本的文字获得能力。
HTTP 1.0:改进请求/回应范式和履行协议,确定三种请求方法:Get、POST和HEAD。
HTTP 1.1:1.0,增加了五个额外请求方法:选择、PUT、DELETE、TRACE和联系。
HTTP 2. 0 (未广泛提供):对第一部分的请求/答复基本相同,但所有第一个键必须全部减少,请求行必须独立于:方法、:scheme、:host、:path。
三.爬虫介绍
1.什么是爬虫?
简单地说, 以网络操作的模拟器取代某人。
2.为什么需要爬虫
为搜索引擎(100度、谷歌等)、数据分析、大数据等其他应用提供数据源。
公司获取数据的三种方法
一. 公司拥有的信息;
2个第三方平台获得的数据(100度指数、数据大厅);
三,爬行动物进入了数据
四,Python作为爬行动物的优势。
一. PHP: 向多线旅行提供不满意的支助;
2, Java: 大代码和它很多;
三.C/C++:大号代码量,难以准备。
Python 4:支持模块、代码简介和发展效率(快速框架)。
5.爬虫的分类
一. 诸如Baidu、Google和Yahu等通用网络爬行动物
2. 关注基于网络的爬行动物:根据预定目标,在特定地点选择性地获取专题内容。
四.重要概念
a. GET 和 a.POST 和 a.GET 和 a.POST 和 a.GET 和 a.POST 和 a.GET
一.GET:在 URL 上显示所有查询参数 。
2.POST:要发送的查询参数和数据隐藏在表格中,不会在 URL 地址看到 。
2.URL组成部分

3. 用户代理用户代理用户
激活:收集关于用户浏览器、操作系统等的信息,以便优化用户对HTML页面效果的访问。
User-Agent:
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
Mozilla Firefox(壁炉内核)
4.Referer
显示当前请求的来源。经常用于反拖网战略。
状态码:
200:请求成功;
301: 不断调整方向;
302: 简要调整方向;
404: 请求失败(服务器无法找到客户要求的资源(页))。
500:内部服务器请求
五.抓包工具
本文由 在线网速测试 整理编辑,转载请注明出处。

