SOME/IP协议详解「2.1.2·Payload数据类型序列化」
- SOME/IP协议详解「2.1.2·Payload数据类型序列化」
- 1 大小端问题
- 2 数据对齐填充问题
- 3 都有哪些数据类型
- 基础数据类型:就是C语言中的保留字能直接使用的类型及其重命名类型。如uint8,short,long和float64等
- 复杂数据类型:就是C语言中需要通过基础数据类型进行组合的新类型。如struct,union,array和string等
- someip不支持指针的直接序列化,因为没有任何意义,通信双方的内容地址和存放的数据都是不同的,直接传地址是去不到对应数据的
- someip支持使用TLV(Tag Length Value)格式传输数据,需要配置打开,后续会有一章专门讲解
最后更新:2022-02-01 21:29:08 手机定位技术交流文章
SOME/IP协议详解「2.1.2·Payload数据类型序列化」
点击返回雪云飞星的SOME/IP协议详解「总目录」
之前简单的概括了一下序列化/反序列化,就是降维打击,从这一章开始到2.1所有章节结束,都在讲解这个降维打击的详细规则与原理。掌握了序列化,才能通过肉眼解析报文,或者手动构造报文,在调试过程中会有很大的帮助
1 大小端问题
首先什么是大小端:
大端:高字节存放到内存的低地址
小端:高字节存放到内存的高地址
假如有一个数据是0x12345678,直接用memcpy将这个数copy到下图中的Length里面来,如果是大端的话,((uint8)Length)[0]就等于0x12;如果是小端的话,就是0x78
因为对于赋值的方便性来讲,大端是网络通信中常用的方式(例如TCP/IP),所以SOME/IP格式头也使用大端。Payload由于是用户自主定义的内容,所以用户可以自己决定大小端
2 数据对齐填充问题
对于不同的CPU,数据的存放有不同的对齐原则,有8、16、32甚至64位对齐(可以配置)。如果一个数据是按照CPU对齐的,那么在反序列化的时候会有一定的性能优势。但是SOME/IP序列化的时候只支持对动态数据类型自动添加填充位(即动态数组、动态字符串)。使用场景比较局限且序列化的时候还会消耗一些性能,博主感觉比较鸡肋,很多时候都默认使用8bit对齐(也就是不对齐)。我们也举个例子简单讲讲: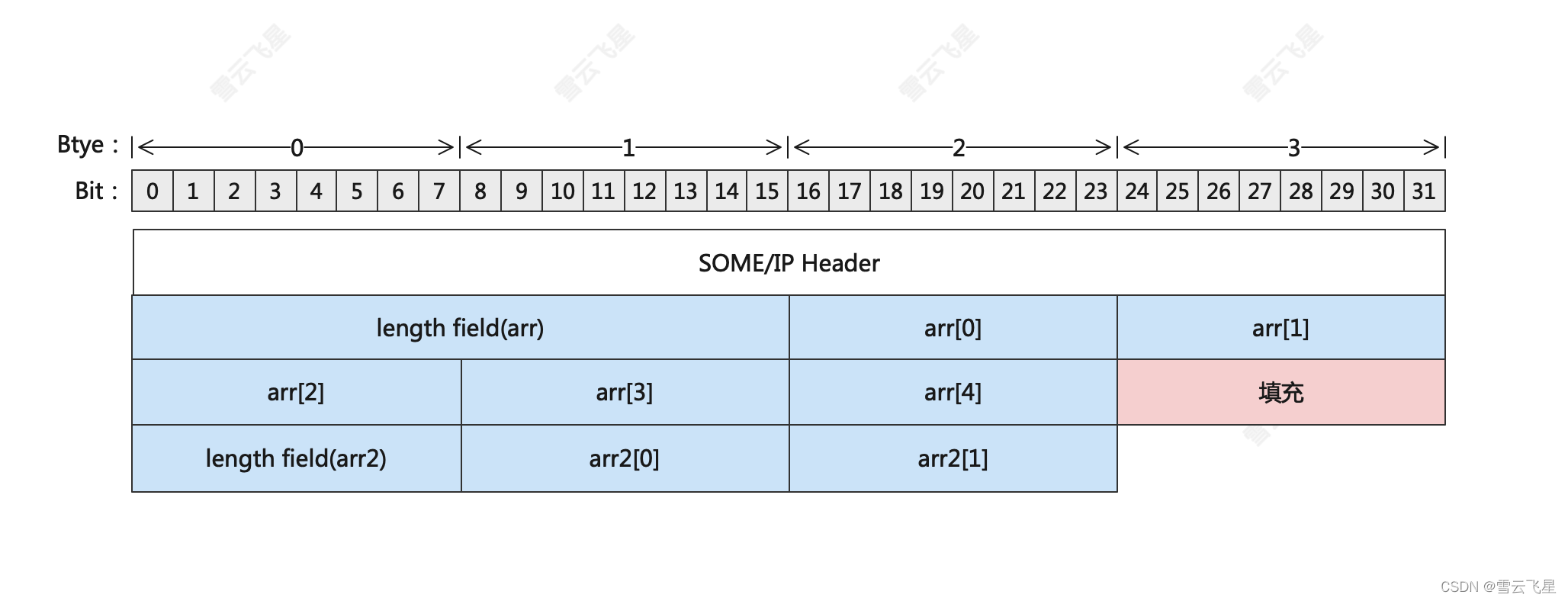
假如我们设计的服务接口有两个参数,一个是uint8 arr[5],另一个是uint8 arr2[2],且假设两个数组都是动态数组。动态数组都是要加长度域的,以表示后面的数组的字节数,假设arr使用2bytes的长度域,arr2使用1byte的字节域。当前CPU是4字节对齐,那么序列化完arr的5个数据后,就不能立即序列化arr2。因为arr的长度域+数据域一共7bytes,不是4的整数倍,要填充1byte。而后面的arr2由于是该someip报文的所有元素的末尾元素,虽然其也是动态数组,但是不用填充(因为后面没有数据了,不会影响后面数据的反序列化性能)
3 都有哪些数据类型
拿C语言举例,能用到的数据类型有:
需要强调的一点是:string和动态array这样的类型在C语言中是不存在的,但是string可以通过array模拟;动态array也可以通过struct模拟。在CP协议中,可以识别这些模拟出来的类型,并序列化成string和动态array。下面列举一下someip所支持的所有可序列化的数据类型
| 类型 | 说明 |
|---|---|
| 基础数据类型 | boolean|uint8/16/32/64|int8/16/32/64|float32/64 |
| 结构体 | struct |
| 字符串 | 包括动态、静态长度string |
| 数组 | 包括动态、静态长度array |
| 枚举 | someip不直接支持enum,但可以将其赋给一个基础数据类型 |
| 位域 | someip不直接支持bit field,但可以附在一个uint8/16/32/64上顺便带过来 |
| 联合体 | union |
需要注意的是:
点击返回雪云飞星的SOME/IP协议详解「总目录」
本文由 在线网速测试 整理编辑,转载请注明出处。

