TCP三次握手四次挥手,流量控制和拥塞控制
- TCP 是基于链接的, UDP 是基于非链接的
- 如果把计算机的通信比喻为人的通信, 人的通信有 2 种方式, 写信和打电话, 这里不考虑速度因素
- UDP 就像写信, 写出去的信不不能保证对方一定收到, 及时对方收到了也不能保证信件一定完整, 即使信件完整也不能保证接受信的顺序和发送信的顺序一致, 甚至对方的收信地址可能是不存在的你也不知道
- TCP 就像打电话, 从拨通电话, 到控制通话, 到挂断电话都能有及时的反馈
- A:发送 syn 包
- B:返回 syn + ack
- A: 发送 ack
- 丢包问题
- 乱序问题
- 发送缓冲区
- 发送报文: 序列号 + 长度 + 数据内容
- 回复确认:的 ack 就是序列号 + 长度 = 下一个包的起始位置
- 切割发送: 根据序列号和长度重组数据
- 丢失重发: 接收端序列号丢失就很容易发现, 重新发送即可
- 接收端通过 ack 回复接收,
- 发送端通过回复 ack 重发数据
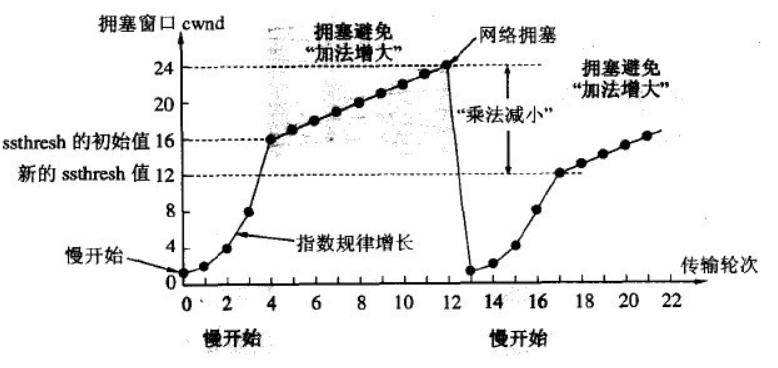
cwnd < ssthresh:慢算法, 阻塞窗口小于限制门槛的时候阻塞窗口呈指数增加cwnd > ssthresh:拥塞避免算法, 阻塞窗口大于限制门槛的时候, 阻塞窗口每次增加 1cwnd = ssthresh:慢算法和拥塞避免算法随意- 将门槛限制 ssthresh 设置为拥塞窗口的一半
- 将拥塞窗口设置为 1, 并开始执行慢算法
- 初始值的拥塞窗口
cwnd = 1, 门槛限制ssthresh = 16 - 开始执行慢开始算法, cwnd 指数级增长, cwnd = 16 时候触发拥塞避免算法 cwnd 线性增长
- 假设在 cwnd = 24 的时候发生了阻塞, 采用拥塞处理, , ssthresh = 12, cwnd = 1(门槛限制为发送窗口的一半, 拥塞窗口为1)
- F : FIN - 结束; 结束会话
- S : SYN - 同步; 表示开始会话请求
- R : RST - 复位;中断一个连接
- P : PUSH - 推送; 数据包立即发送
- A : ACK - 应答
- U : URG - 紧急
- E : ECE - 显式拥塞提醒回应
- W : CWR - 拥塞窗口减少
最后更新:2022-02-20 00:59:18 手机定位技术交流文章
tcp三次握手四次挥手
如何理解
TCP(Transmission Control Protocol): 传输控制协议
UPD(User Datagram Protocol): 用户数据协议
三次握手建立连接
A: 恋爱吗? SYN
B: 我爱你 SYN + ACK
A: 我也爱你 ACK
四次回收断开连接 FIN
A: 分手吧 FIN
B: 好吧 ACK
B: 是我不够帅么 FIN
A: 是的 ACK
巧记: 三次握手服务器返回的 2 个包是否是一起发送的, 因为服务端只有一次机会了
四次服务器握手是先 ACK 在 FIN 分开的,因为有 4 次机会.
三次握手
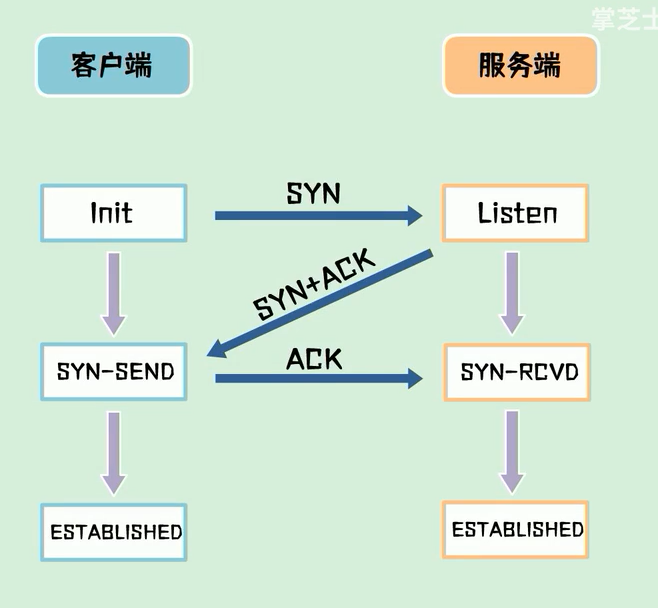
为什么要 3 次握手
在不可靠的信道上建立可靠的连接
如果是 2 次握手的话客户端发送 syn1 阻塞,
客户端重新发送 syn2 成功, 服务端返回 syn2 + ack 建立连接
客户端发送的 syn1 阻塞结束, 服务端收到 syn1 返回 syn1 + ack
服务端以为建立了 2 个连接 , 客户端只建立了一个连接, 造成了状态的不一致
通话控制
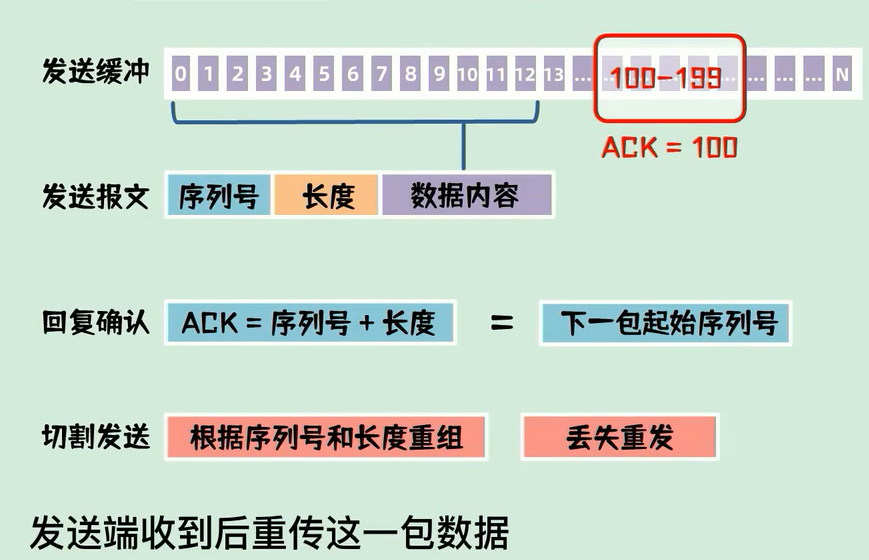
hello
发送端: 发送数据0 | 2 | he,2 | 2 | ll,4|1|o
接收端: 回复ack 0 | 2
四次挥手
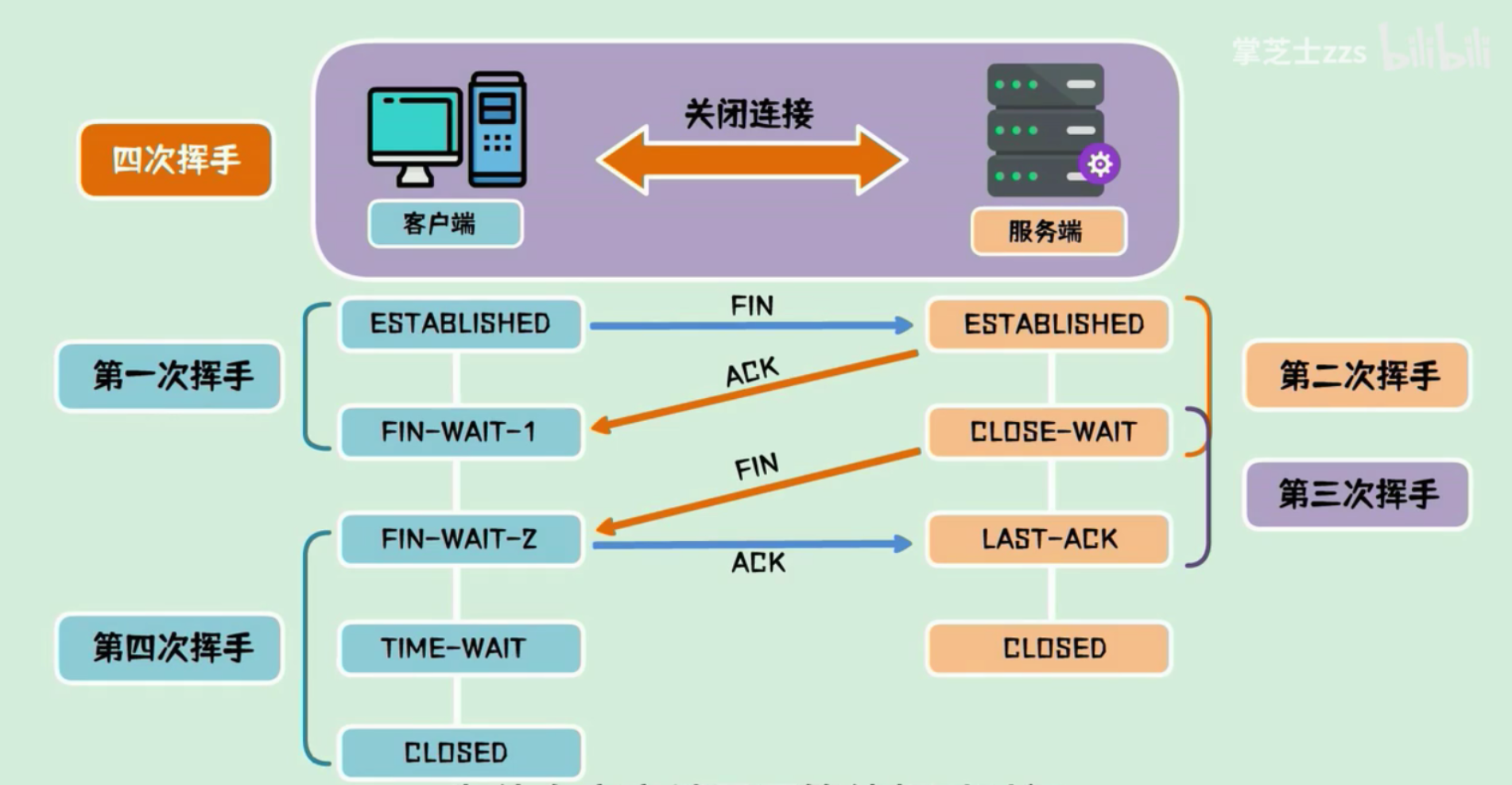
A: 发送 fin 包
B: 回答 ack 包
B: 回答 fin 包
A: 回答 ack 包
A: 超时等待保证 B 收到最后的 ack 包,因为 B 没收到会重新发送 fin 包刷新超时时间
超时等待
同样是为了在不可靠的信道里面创建可靠的连接
因为没有保证 B 最后一定能收到 A 发送的 ack 包, 如果 B 超时没有收到 B 会重新发送 fin 包, A 刷新超时时间并且重新发送最后的 ack 包.
tcp 流量控制, 拥塞控制
一: 流量控制
1. 为什么需要流量控制
举个例子类似百度网盘限速就是流量控制
解决的问题就是发送端发送数据过快接收端来不及接收导致的数据分组丢失
即使通话控制中有 ack 重发机制, 但是如果发送端 10M 带宽, 接收端 1M 带宽就会数据一直丢失, 一直重发, 这是不合理的, 我们应该限制发送端的速度
2. 怎么实现流量控制
滑动窗口
通话控制中接收端 ack 确认会返回接收的序列号和长度
发送端的滑动窗口: 利用接收端的 ack 数据的序列号+长度控制自己数据的发送
接收端的滑动窗口: 利用发送端数据封装的序列号+长度来实现分组无差错, 有序接收
3. 流量控制死锁?
发送者收到一个长度为0的 ack 就会停止发送, 等待发送者的下一个应答, 如果发送者的下一个应答在网络中丢失就会导致死锁
为了避免死锁, tcp 使用了持续计时器, 发送者接收到长度为0的 ack 之后就开启计时器并停止发送, 计时器到了就主动发送报文询问接收到窗口的大小, 如果窗口长度还是为 0 就重置计时器并等待
拥塞控制和流量控制的区别
流量控制是用来限制发送速度的, 类似百度网盘限流
流量控制: 接收端控制发送端的速度, 防止数据包丢失
拥塞控制: 发送端自己控制发送速度, 防止网络阻塞, 常见的方法有: (1) 慢开始(2)拥塞避免(3)快重传(4)快恢复
二: 拥塞控制
我们假定数据是
(1) 数据是单向传递的
(2) 接收端的缓存足够大
就是说发送端窗口的大小由网络的拥塞程度决定
1. 慢开始算法
发送端维护一个拥塞窗口(congestion window)的变量, 发送窗口的大小等于拥塞窗口(congestion window)
拥塞窗口的大小从 1 开始, 每一个往返时间RTT(round trip time)后, 拥塞窗口的大小等于之前的 2 倍
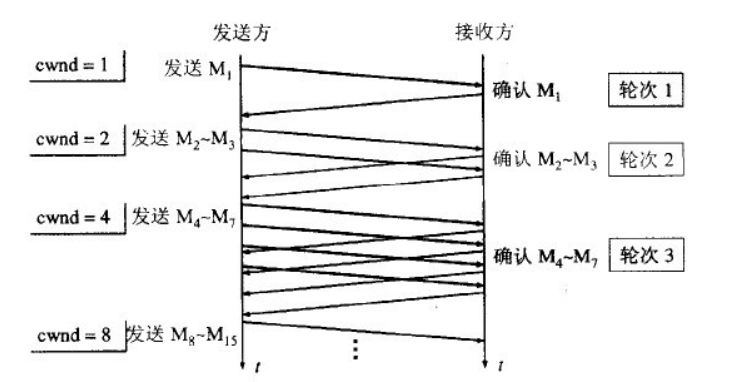
上图可以看出, 一开始拥塞窗口 cwnd 是 1, 每一次传输或者说是往返时间 RTT 都增加一倍
这就是为什么我们下载一个软件的时候前期的速度总是很慢(所以叫慢开始), 然后不断增加到正确的数值
2.1 拥塞避免算法: 限制门槛
为了防止 cwnd 呈指数级增长过大导致网络拥塞, 我们做了一个限制门槛ssthresh
下面介绍拥塞避免算法
2.2. 拥塞避免: 拥塞处理
上面的慢算法和拥塞避免算法都是为了避免网络拥塞, 但是根据墨菲定律法则:网络是一定会拥塞的
网络发生拥塞如何处理呢?
无论是慢算法还是拥塞避免算法, 如果网络拥塞(没收到 ack 确认)
拥塞处理流程如下
关于 乘法减小(Multiplicative Decrease)和加法增大(Additive Increase):
“乘法减小”指的是无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞,就把慢开始门限ssthresh设置为出现拥塞时的发送窗口大小的一半,并执行慢开始算法,所以当网络频繁出现拥塞时,ssthresh下降的很快,以大大减少注入到网络中的分组数。“加法增大”是指执行拥塞避免算法后,使拥塞窗口缓慢增大,以防止过早出现拥塞。常合起来成为AIMD算法。
拥塞避免只能避免拥塞, 并不能解决拥塞问题, 当发生拥塞丢包之后解决方法还是重传
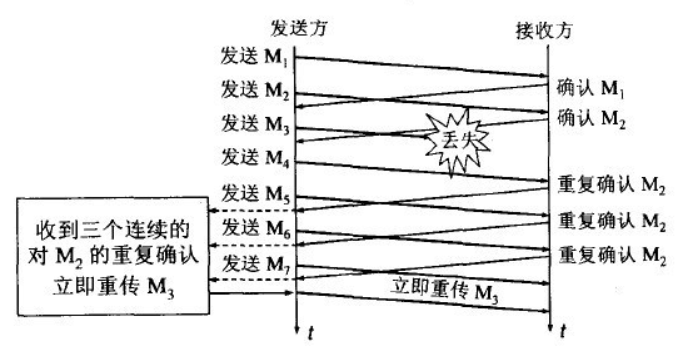
3. 快重传算法
接收方如果发现丢包了(包的封装由序列号和长度, 对不上就是丢包了) 就立刻发出重复确认(为了是发送方提前知道丢包了, 而不是最后再告诉发送端丢包了, 可以提高网络吞吐量20%)
发送端收到接收端 3 次重复确认的 ack 就应该马上重新发送丢失的包
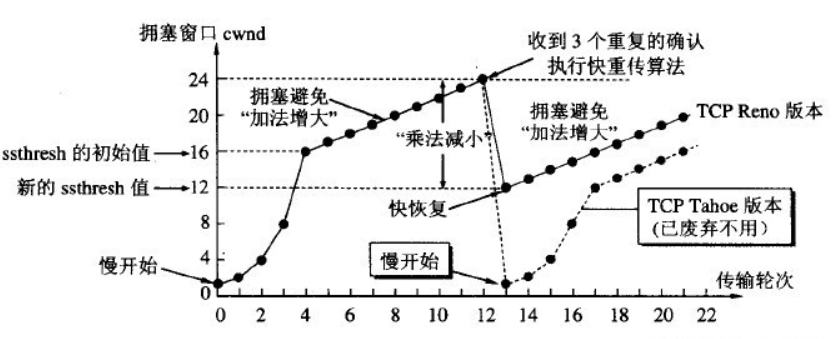
丢包之后可能已经发生网络拥塞了, 为了防止网络继续拥塞, 老版本的TCP发送端会采用拥塞避免算法: 拥塞处理(ssthresh为cwnd的一半,cwnd为1), 然后慢开始算法
但是因为能收到 3 个重复的 ack, 表明网络也不是特别拥塞, 新版的TCP发送端会使用快恢复算法增加吞吐量
4. 快速恢复算法
门槛限制 ssthresh 为阻塞窗口 cwnd 的一半, 执行拥塞避免门槛限制线性递增(而不是慢开始算法)
TCP 几个标记
refrence
上面的仅仅是个人总结和理解, 参考如下.
一条视频讲清楚TCP协议与UDP协议-什么是三次握手与四次挥手_哔哩哔哩_bilibili
TCP流量控制、拥塞控制 - 知乎 (zhihu.com)
https://blog.csdn.net/weixin_40784198/article/details/81434530
本文由 在线网速测试 整理编辑,转载请注明出处。

