应用层协议设计ProtoBuf
- 一、协议设计
- 二、对体制框架的全面审查
- 三、协议设计范例
- IM即时通讯
- 云平台节点服务器
- nginx
- http
- redis
- 四. json、xml和Protobuf之间的顺序比较
- 协议安全
- 协议升级
- 五. 理由分析和Protobuf工程实践
- 使用Protobuf的工程实践
- 原理
- 由于HTTP协议只是一个框架,没有具体说明如何对包件进行排序,因此必须与其他顺序方法结合使用,以交流商业逻辑数据。
- HTTP协议效率低下,难以使用。
在某些情况下,可使用HTTP协议: - HTTP协议是公共网络用户API最渗透最广的,因此最合适;
- 它没有那么有效
- 预计将提供更熟悉的界面,如新波和福音传教运动提供的开放界面。
XML 代表exenable Marcup 语言, 它是一种流行的高质量数据交换标准。 本地设置、 ui 配置、 qt 和 André 场景中常用 。

JSON(JavaScript Objectal Noteation,通常称为JS Objective Profile)是一种流行和轻量级的数据交换格式。文字结构储存。网站http,注册账号,网络上有许多登录需要做。

最后更新:2022-03-31 08:11:54 手机定位技术交流文章
文章目录
一、协议设计
有协议有什么意义?
例如,在qq聊天场景中,
文字聊天
文字当中有表情
语音聊天
要求《议定书》的设计要在两个终点之间进行沟通。
如果你不创建协议 客户不知道它是如何沟通的
二、对体制框架的全面审查
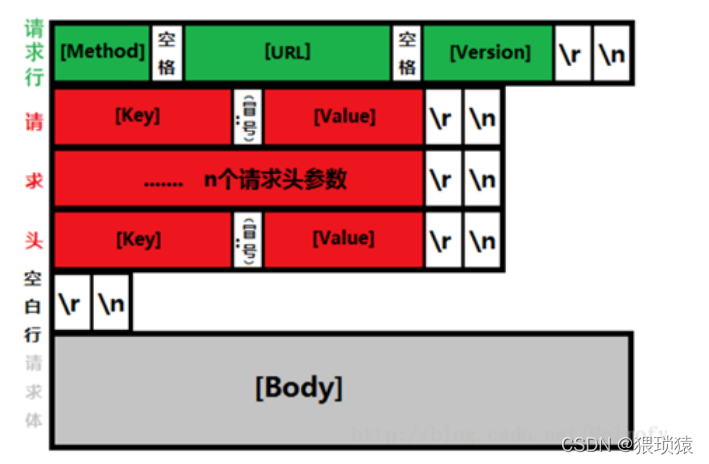
在 qq 对话框中键入文本并传输时,例如,使用信件框的完整性,例如换行符。
方式有这些
以特定的符号( 如 rn) 拆分, 当读取字节流中的此字符串时, 表示最后的信件会终止, 如我们 http 的顶部, 每一行都会被此符号分隔 。
它有一个固定的信息信头和机体结构。这个结构的通用信息头是一个固定长度的结构。此外,信头中还有一个参数,该参数设定信息体的大小。收消息时,先收到固定的字节号头。这条信息的全部长度已经解决 。您可能会收到如此长的讯息 。这是互联网上最常用的通信格式:标题+body。
当缓冲线被排序时,在头部添加字符流。这就是 http 和 redis 如何使用 。收到消息后,您将能够知道数据是否包含端点。未收到信件:%s%s这篇文章是全球之声在线特稿的一部分。按此长度接收消息体
三、协议设计范例
IM即时通讯
length=head+body
你如何辨别聊天软件 和匿名与电工谈话的区别?
为了辨别它,我们会使用Appid。我们可以分辨几个商业应用程序的区别。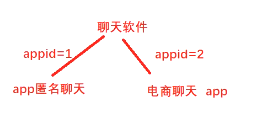 聊天组、 service_id 和命令_id 均为有效值。
聊天组、 service_id 和命令_id 均为有效值。

左上方的登录数据、 左上方的数据、 左上方的数据、 以及服务器对信件的访问权限, 都在代码中可见 。 那么,这个后遗症有什么影响呢?
那么,这个后遗症有什么影响呢?
例如,Tcp保证电文得到答复,但不保证业务得到处理,而公司则通过后续方式对客户作出答复。
云平台节点服务器
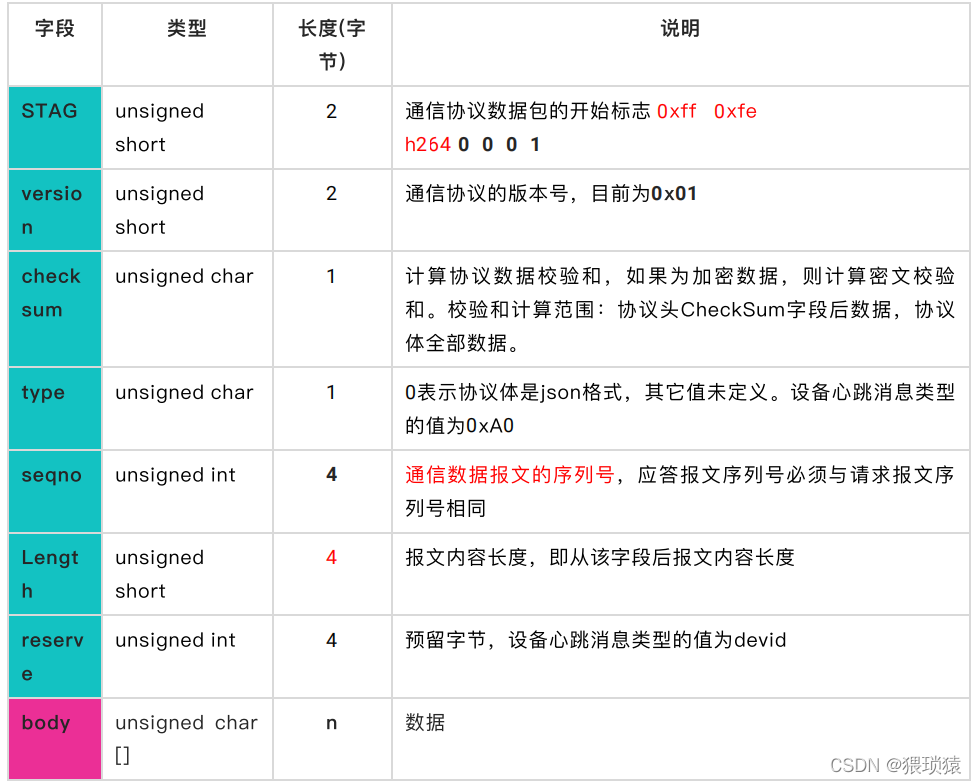
通讯协议数据包启动标记的起始标记
你知道,类型,窗口和安德烈可以使用原生泡泡, 不像一台51,Stm32, 不能使用原生泡泡的机器。
身体的长度不包括头部的长度。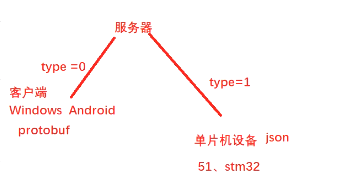
协议是自定的,顺序协议,如json和Protobuf,可以是标准协议。
nginx
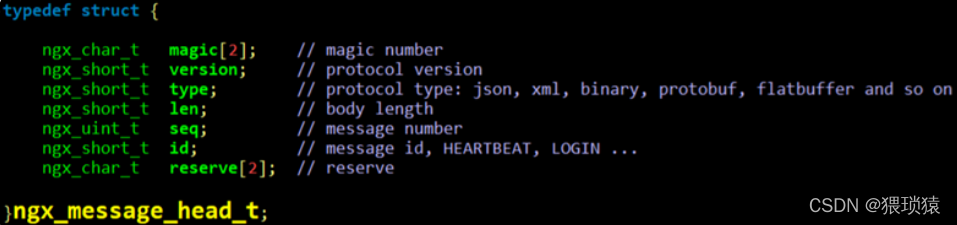
http
我们最受欢迎的协议是HTTP协议,我们能否利用HTTP协议作为互联网上的后台协议?
redis
想法是先发送字符串以显示参数数量, 然后逐个发送参数, 当发送每个参数时, 先发送字符串以显示参数的大小, 然后传输参数的内容 。
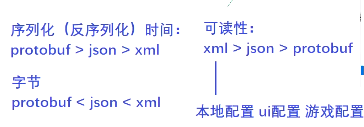
四. json、xml和Protobuf之间的顺序比较
TLV代码及其变异(TLV代表标记、长度和价值):Protobuf。
文本流编码: 例如, XML/ JSON
固定结构编码的基本前提是,双方就传输场的类型和含义达成了协议。在某些方面,它类似于TLV。但是,没有标签和Len,只有value,例如,TCP/IP内存倾弃:推理如下:内存中的数据直接导出。不执行任何相继操作 。反序列化的时候,直接还原内存。
大众序列规程包括xml、json和protobuf。
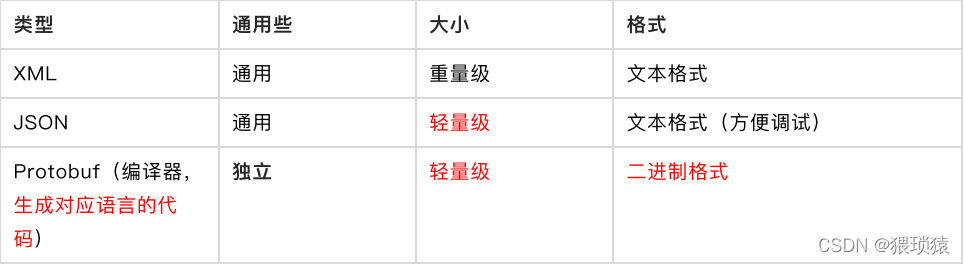
协议缓冲是谷歌的独立和轻量级数据交换格式。 存储在二进制结构中 。 内部、 服务器之间的 Rpc 呼叫、 即时信息, 以及更多用于游戏商品 。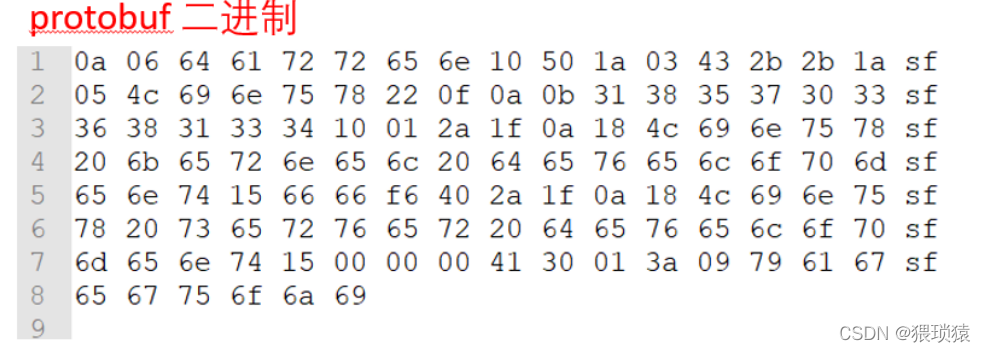
协议安全
我道歉,Csdn,这个职位是我们特别报道的澳大利亚网/gsls200808/article/ details/48243019。
AES固定键(https://ww.flickr.com/)我不知道你指的是什么,Yuque。#AES细节)
openssl
信号协议是端对端通讯加密标准(https://ww.flickr.com/)。# 信号协议开放源知识)
协议升级
协议增强 = 添加字段
⼤版本
按版本号确定协议的版本,即按版本号区分不同种类的协议。
支持协议的负责人可以延长,即在构建协议的负责人时,有一个字段来确定负责人的长度。
五. 理由分析和Protobuf工程实践
使用Protobuf的工程实践
这是谷歌的私人交易,只是最近才开的,不是世界标准
《议定书》缓冲器是一种语言中立、平台中立的数据格式合成器,可用于通信协议、数据储存等。
礼宾缓冲作为测序的数据源。它是灵活的,⾼效的。例如,XML。《议定书》缓冲区的限制要大得多。更加快速,更加简单。在确定待处理数据的数据结构之后,《议定书》缓冲代码生成工具可用于生成必要的代码。即使没有必要重新部署行动,数据结构也可以修改。简单地用Protobuf来描述数据的结构。以多种语文或来自各种数据来源的结构化数据可以轻松地阅读和编写。
协议缓冲适用于数据存储或 RPC 数据交换格式。 可用于通信协议、 数据储存不重要、 平台无关紧要、 综合数据格式是可缩放的 。 抱歉, 但我不明白您在说什么 。
原样类型文件命名惯例
项目 Modules. 原型
proto命名空间
项目.模块
引用文件
多个系统都使用同样的原型文件。
Andre, Windows 客户端和服务器都使用相同的原始文件,如果不使用,则导致数据在平台之间不同步。
编号用于识别原药字段。
例如,字符串 user_name=1 被传送到服务器,服务器确认该数字为用户名。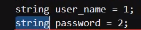
由于编号可能决定顺序, 此字符串用户_ name=1 具有一致的字段顺序, 传送和接收, 独立于软件包的位置, 数字匹配以识别合适的字段值 。
重复关键字的使用与数组类似,其中内置类型的数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组数组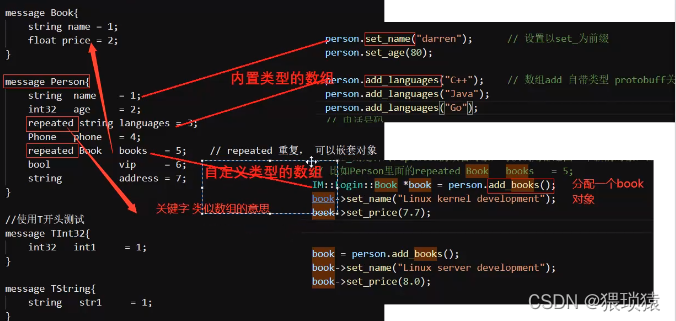 顺序数据,即人们的东西 以特定顺序填充。
顺序数据,即人们的东西 以特定顺序填充。
反序列化
重要的关注是使用何种物体来传输测序数据,而当我们建造该字段时,该字段是在协议的开头给出的。
并且“ phone” 的名称不是指变音。 如果 phone () 删除字段, 电话代码会失败。 服务器将不识别数字 4 。

原理
二、印度的组织结构和组织结构
5bit 3bit
field num<<3|wire type value
客户必须同意服务。 就价值而言,共有128种不同的选择。
就价值而言,共有128种不同的选择。
通常,普通的 Int数据类型, 不论值大小, 是相同的存储空间, 并且这可能会促使人们思考 瓦林茨代码的价值是否使用每个字的最大有效位置作为信号, 以及其余的7个位子是否以两位数补充的形式 来存储价值本身, 在这样的情况下, 最大数是 1, 值随之而来, 当最大数为 0, 整数代码的数量 已经是最后一个整数, 为了实现这一点, 瓦林斯代码使用每个字中 最高有效位置作为信号, 而其余的7个位子 以数字本身的两位数补充形式存储,
 然而,只有最后一个字节有正当的价值;前三个字节全部是零,如果瓦林茨编码,每个字节中最高的字节不能直接用来表示我们的价值。它用来确定字节是否终止。0代表结束),其⼆进制形式为
然而,只有最后一个字节有正当的价值;前三个字节全部是零,如果瓦林茨编码,每个字节中最高的字节不能直接用来表示我们的价值。它用来确定字节是否终止。0代表结束),其⼆进制形式为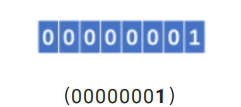 举另一个例子。背景中的绿线是一个恢复程序。
举另一个例子。背景中的绿线是一个恢复程序。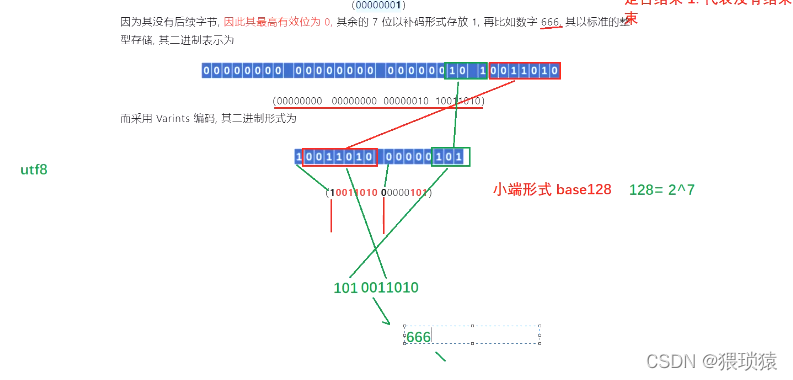
其最大有效性为0,因为没有后续的字节,其余7位数以补充代码的形式保存,如以标准十六进制格式储存并以二进制术语表示的66号,因为没有后续字节,所以其最大有效性为0,其余7位数以补充代码的形式保存,如以标准矫形格式储存并以二进制术语表示的66号。
首先,我们可以尝试将128 Varints基地代码的二进制字符串 恢复到最有效的地方。 由于128 Varints基地使用一个很小的字节序列,而且低地址的数字很高,因此这些标记随后被删除。
由于128 Varints基地使用一个很小的字节序列,而且低地址的数字很高,因此这些标记随后被删除。
删除标记位置,颠倒字节顺序,以获得原编号1010011010,即66。
从上述编码过程可以看出,不同大小数字的可变整数代码是不同的,代码的原则与CPU的间接位置相似。 CPU用来确定是否要稍稍到达终点,但用这种方式存储数字,而相对较差的方面是,随机搜索序列值是不可行的,因为每个数字的存储空间不是对称的,因此不可行。
此外,还使用了二元编码变体。
在我面前的数字 赤道后面的字节
Varints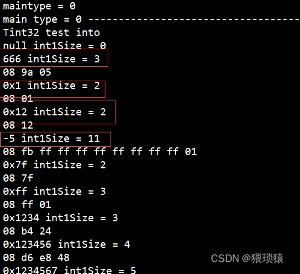
网络类型尝试不超过15位数,原型是小端存储,如果我们的字段经常改变, Json 可以使用。


本文由 在线网速测试 整理编辑,转载请注明出处。

