Netty之拆包粘包原理分析
服务端读取两个完整的数据包A和B,无拆解/粘合问题。
服务端获得A和B中粘合在一起的数据集,服务端必须解构A和B。
服务器接收整个A和B数据包B-1的一部分,它必须解构整个A,等待阅读整个B数据包。
服务器在等待整个A包时,收到一块A包A-1;A包很大,服务器必须多次收到。
消息长度
消息分隔符
消息内容
delimiters
分隔符指的是特定的分隔符。 参数类型是 ByteBuf。 由于 ByteBuf 传输一个数组, 我们可以同时提供多个分隔符, 但我们最终会选择最短的分隔符来分隔 。
例如,收件人可能收到下列电文:
hellonworldrn
在此点, 指定多个 n 和 rn 分隔符; 将选择最短的分隔符解密符, 并获取以下数据 :
hello | world |
maxLength
指定信件的最大长度限制;如果提供的分隔符在最大 Length 后不被识别,则生成 TooLongFrameException。
failFast
表示容错机制,它与最大连字符一起工作。如果失败是事实,那么TooLongFrame 异常值超过最大值时会被丢弃 。不再进行解码。如果失败 Fast=false, 那么因此,我们等到我们解码了整个信息之后,再扔给ToLongFrame例外。
stripDelimiter
它的作用是检测解码后电文是否去除分隔符,如果条形Destricter=false产生特定的分隔符 n,则数据解码按以下方式进行。
hellonworldrn
当限制条被设定为虚假时,以下内容将被解码并获得:
hellon | worldrn
lengthFieldOffset
长度字段的偏差,或记录长度数据的起始点。
lengthFieldLength
以长度字段锁填充的字节数, 用于指定信件长度的字节数 。
lengthAdjustment
在一些更为复杂的协议设计中,长度域不仅包括电文长度,而且还包括诸如版本号、数据种类、数据状况等额外数据,我们可以在哪个时候使用英文调整来校正,值=包件长度--长度域值。
initialBytesToStrip
解码后要跳过的字节数, 与信件内容字段的开始相对应 。
lengthFieldEndOffset
以财产价值= ength Fieldoffeset+lean FieldLength 表示的长度字段结尾部分的冲抵
因为长度字段在文章开头, Ength Fieldoffest=0 。
长度Length=2 协议设计指定固定长度为两个字节。
长度调整=0,外地质量保证信息长度,无需调整
解码为长度+内容,如果初始位元TToStrip=0,则无需跳过任何早期字节。
因为长度字段在文章开头, Ength Fieldoffest=0 。
长度Length=2 协议设计指定固定长度为两个字节。
长度调整=0,外地质量保证信息长度,无需调整
位元TToStrip=2 绕过长度字段的字节长度,解码位元Buff 以只包含字体字段。
因为长度字段在文章开头, Ength Fieldoffest=0 。
长度Length=2 协议设计指定固定长度为两个字节。
拆解所需长度为长度调整=-2,长度13字节,需要减少2字节。
启动进程时使用了位元TToStrip=0。 解码仍然是长度+内容。 不需要跳过第一个字节 。
Ength Fieldoffeset=2 必须绕过页眉占据的两字节, 这是 长度的起始位置 。
长度Length=2 协议设计指定固定长度为两个字节。
长度调整=0, 长度字段仅包括信件长度, 无需修改 。
启动进程时使用了位元TToStrip=0。 解码仍然是长度+内容。 不需要跳过第一个字节 。
要成为长度的起始位置, ength Fieldoffest=1 必须跳过 hdr1 的一个字节 。
长度Length=2 协议设计指定固定长度为两个字节。
长度调整=1, 长度调整=1, hdr2+内容总计 1+11=12字节, 长度字段值 (11字节), 长度字段值 (11字节) 和长度字段值 (11字节) +
上英文调整(1) 检索 hdr2+ Content (12 字节) 的内容 。
开始时的字节ToToStrip=3, 以 3 字节在 hdr1 和长度字段中解码
Ength FieldLength: 2, 这意味着长度需要 2 字节 。
起始位元组ToStrip: 2, 意指解码是通过跳过两字节长度和获取内容完成的。
最后更新:2022-04-18 10:31:51 手机定位技术交流文章
一,什么是贴纸袋?
TCP传输协议以数据流传输为基础,对数据流动没有限制。当客户将数据传送到服务处时,整个数据电文可分成小部分分发,或将多份提交书合并成大部分分发,在数据流传输的基础上建立多份传输协议,对数据流动没有限制。当客户将数据传送到服务处时,整个数据电文可分成小部分分发,或将多份提交书合并成大部分分发。
在这种情况下,可能出现下图所述的情况:
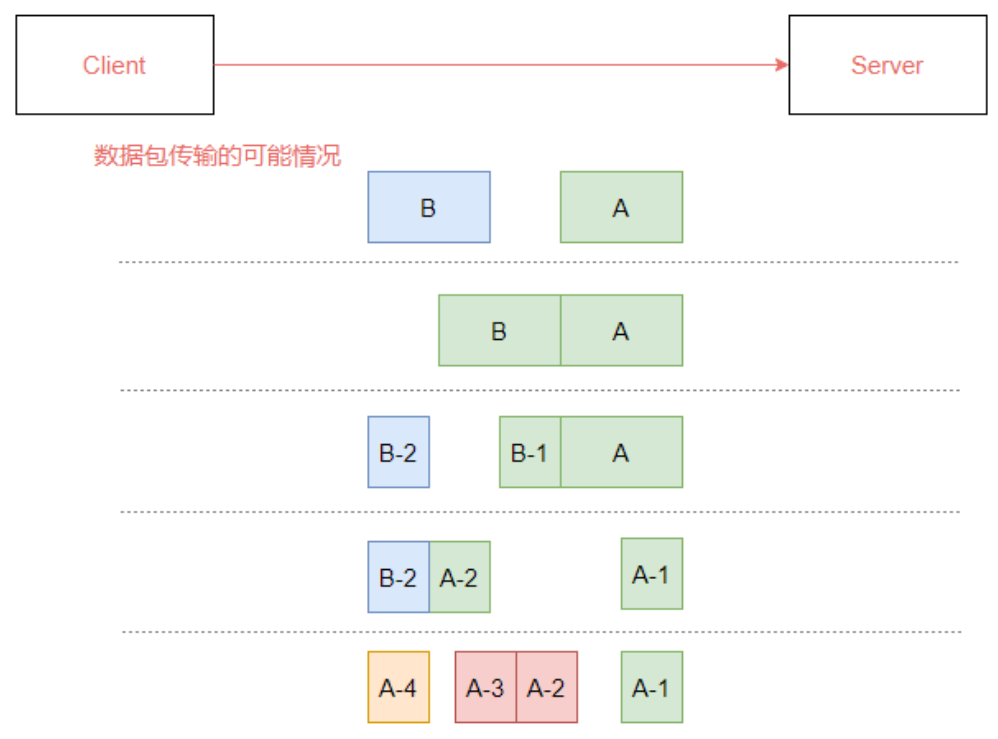
由于拆解/裂缝问题,收货人难以确定包件的边界在哪里,并可能读取部分数据,造成数据解答问题。
二. 应用层面的通信协议规格
那么,我们如何处理包装和粘粘袋的问题?
想法同样简单:通信当事人商定通信协议,服务端在收到电文后,根据谈判达成的协议解码,以避免粘贴和无包装问题。
当你仔细考虑的时候,不难弄清楚。在解包后解决电文内容问题的原因是无法从源获取信息。这是因为程序无法检测到完整信息。我不确定如何将那些被解封的信息合并成完整的信息。然后根据单一规则将粘贴的包数据分成许多完整信息。因此,从这个角度来看,我们所需要的只是双方商定的信息识别规则。
二.1 电文长度现已固定
当接收者累积读出规定的长度报告时,即判断已获得完整电文,当发送者的数据短于固定长度预设信息时,即需要填补空位,当接收者累积读出规定的长度报告时,即认为已获得完整电文,而当发送者的数据短于固定长度时,则需要填补空位。
如下图所示,假设固定的电文长度为4,则不超过这一长度的电文必须用空位填充,使电文能够形成一个整体。

这一解决办法是直截了当的,但缺点是显而易见的,因为不清楚如何为没有固定长度的新闻设定长度,如果为大会生产字节浪费而设定长度,则影响信息传输的长度太小,因此一般不会发生这种情况。
2.2 特定分隔符
能否在电文中添加拆分, 因为无法将其除以特定的长度 。 然后该电文由收件人使用指定的分隔符( 如以下图像所示 ) 进行分割 :

在使用指定分隔符的情况下,必须注意确保分隔符与电文正文的字符之间没有冲突,否则会发生电文分割错误。
信件长度 + 信件内容 + 分隔符
正如你在Redis中可能看到的那样,数据通信取决于电文长度加上电文内容加上分隔符,在Redis协议中描述如下:
人们发现,案文有三个方面:
这种方法在项目中广泛使用。最初,电文头的总长度决定全电文携带的参数数量。然后在消息体中,我们有很多事情要处理, 因为信息长度长, 以及信息的内容作为一个组合。最后,我们分道扬镳。在服务器收到此信件后,它做了以下工作:这项规则允许执行完整命令。
4个动物园的2个协议
Zookeper,一个自我定义的信息协议, 使用黄麻协议。
以下是协议请求书的定义:
Xid变量用于存储客户请求的序列号。保证对具体客户请求的回复按正确的顺序进行。按作业类型要求的作业类型节点的形成、节点的去除和节点数据的收集都是常见的。协议的索赔内容是指请求书的主要部分。包括所有要求的行动。不同的请求类型,请求机构的结构不同。
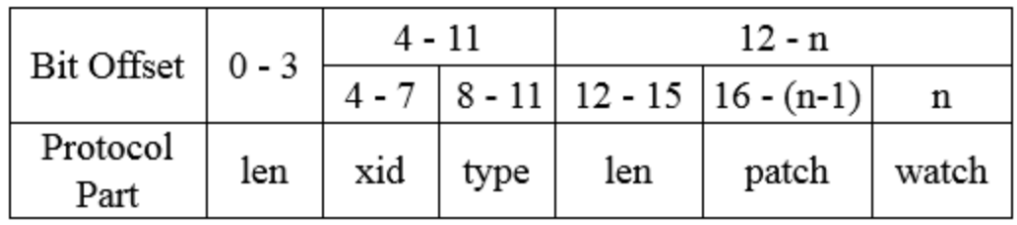
以下是反应协议:
对协议的回应中的 xid 与请求中的 xid 匹配,仅返回请求中的原始 xid 。
Zxid是动物维护者服务器上最新的服务 ID 。这是一个错误代码,但它是一个错误代码。当请求处理过程中发生错误时,它会在错误的代码中标记 。协议的反应要素是指答案的主要组成部分。保存所有回复的返回数据 。不同的响应类型,其答复有一个独特的结构。
3. 案例准备
在进入Netty编码器之前,我们可以建立Netty服务器和客户,以便更容易跟踪案情陈述。
3.1 服务端
处理器
3.2 客户端
处理器
3.3 测试
以下是服务端客户个案,该个案建在Netty,使服务能够接受客户信息;客户连接到服务端返回后发送信息并接收服务端返回的数据。
我们正在执行服务和客户观察效果。
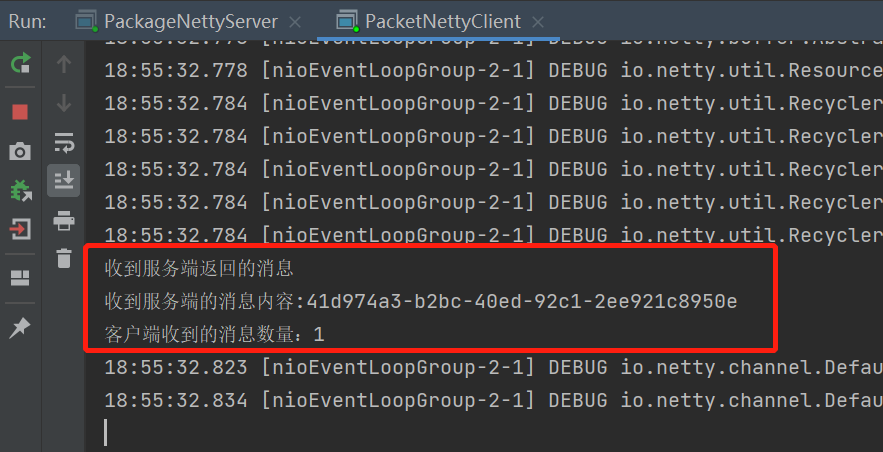
可以发现,当客户启动时,连接成功接收和接受服务返回的数据;起初,一切都似乎没事,但如果我们重新启动下级客户,会怎么样?
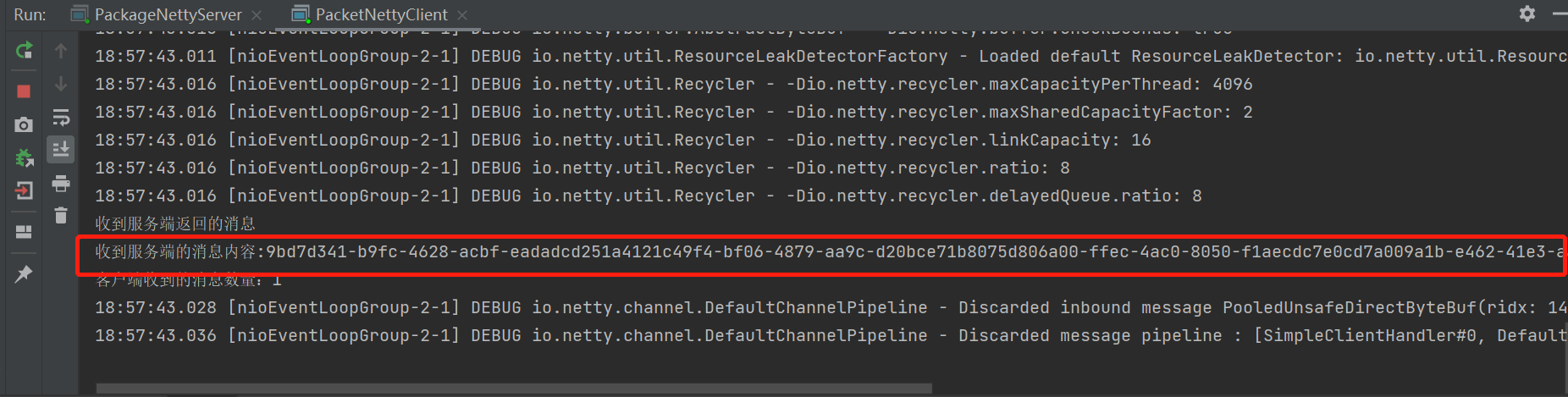
这一次,收到了一条信息,但数据显然不正确。他刚刚归还了所有数据;我们如何将数据分开?
这就是包的问题所在。
四,使用Netty的编码器。
为了克服无包装贴纸的问题,Netty的违约为我们提供了一些标准编码器,下面是使用许多解码装置的快速例子。
4 固定LengthFrame 解码器
固定长解码装置固定LengthFrameDecoder基本工作。这是建立固定信息长度框架的建设方法。无论接受者在任何特定时间获得多少数据所有东西都会按照框架解码
如果总读数长度等于框架长度信息,则该信息无法读取。然后,解码器将假定收到了完整的信息。如果信件的长度小于框架Length, 它是不够的 。因此,在下一个数据包到达之前,解码器将闲置。当您知道所提供的长度时,此函数返回。
使用方法如下:
剩下的全部是,在服务端的活动管理部增加一个固定的长度标准,并将长度定为36(与上述服务端一起收到的UUID长度为36)。
可以看出,长度除以36。
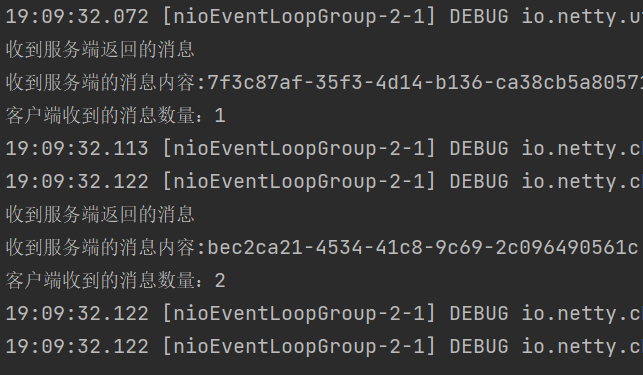
2.2 基于划界器的4个框架代碼器
基于定义的框架代碼器是一个特殊的分隔符解码器,具有以下特性:
使用方法如下:根据&分割。
四. 以工龄长度为基础
长度基于战地框架Decoder是一个大面积的解码器。这是最常用来解开袋子的解码器根据捆绑的长度,它涵盖了大多数设想情况。解码器用来解码开源信息“火箭MQ”的中心。
让我们首先解释一下解码器的主要参数:
这些因素难以理解,因此我们将在几个例子中加以说明。
四.三.1 电文长度+电文内容解码
鉴于存在由长度和电文内容组成的数据包,如下图所示,其中长度指定电文长度,以16位数表示,共有两个字节,协议的相关编码参数如下:

3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3
如果我们只是希望解码结果包含信息,我们可以将其余内容留待一旁,如下图所示。
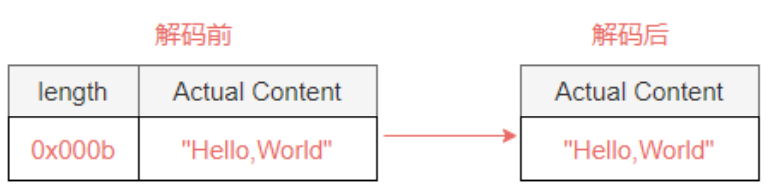
信息存储在四. 3. 3长度的字段中。
如果长度字段包括长度字段本身的长度和内容字段覆盖的字节数量,则长度值为 0x00d(2+11=13字节),在这种情况下,将解码参数合并如下:
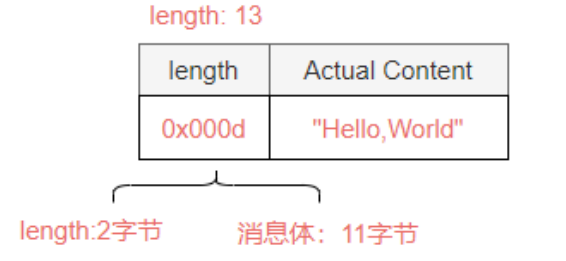
基于长度的外地偏差(4.3.4)
如下图所示,长度字段不再是划界案的起点,长度字段的值为 0x00b,表示内容字段的11 字节,因此,解码参数的配置如下:
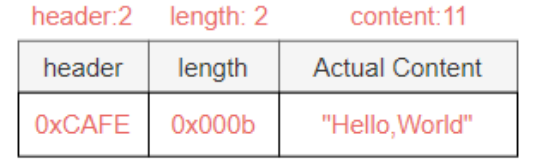
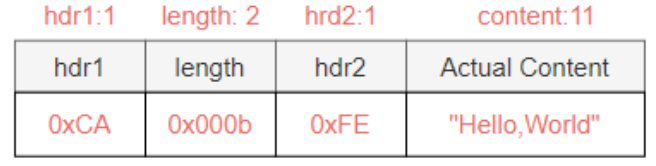
基于长度变差和长度校正(四.三.5)的代谢
如下图所示,长度字段由 hdr1 和 hdr2 字段组成,每个字段有一个字节,与长度字段有差异,并需要修改英文调整,其参数调整如下。
4.4 解码器实战
例如,考虑以下信息信头:客户端通过电文协议传输数据,服务器在到达时必须解码电文。

定义客户端, 从长度部分开始, 可以用 Netty 自己的长度 FleldPrefer 进行, 计算当前信件的二进制字节长度, 并将其添加到 ByteBuf 的缓冲区头 。
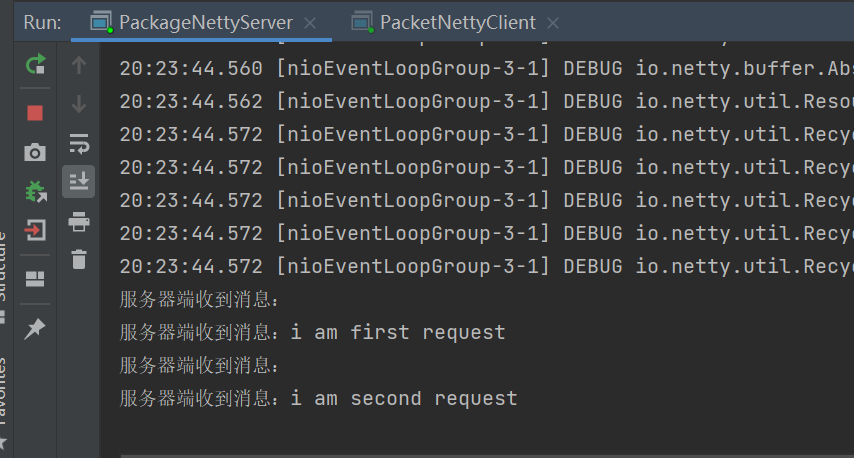
代码执行后,您将收到两份通知。

服务器终端代码如下:
我们不是在这里处理编程问题。
5. 项目地址
Netty 拆卸的粘性分析
本文由 在线网速测试 整理编辑,转载请注明出处。

