3D 人体姿态估计简述[转]
'gt'2D 位置注释'detection'2D HPE 算法输出文件'pipeline'2D HPE算法直接输出GetRootCenteredPose3D 所有关键地点的3D坐标减去根3D联合坐标的坐标,即,在此处的坐标下,原点是根连接点。应当指出,视频Pose3D不适用于作为独立治疗的3D套套管。正常治疗现在包括简单基线3D。ImageCoordinateNormalization根据原始图像的长度和宽度,将 2D 坐标对准到 [-1, 1] 区域 。RelativeJointRandomFlip:对输入 2D poce 和等效的 3D poce 进行随机右手翻转。 2D poce 使用零作为转弯中心,而 3D poce 使用根接头作为转弯中心。PoseSequenceToTensor:将形如[T,K,C]_ 其他协调员[K*C, T]TCN接受这一意见作为投入。Collect数据整合对培训至关重要。
最后更新:2022-05-12 01:45:51 手机定位技术交流文章
[摘自] 3D 3D 假设的人类姿势简述 -- -- 隐蔽
0 前言
3D 人类阴茎估计(3D HPE)的目标是估计重要人类点在三个方面的位置。3D HPE应用非常全面。人的互动、练习分析、康复等等都是其中的一部分。它还可以提供关于其他计算机视觉活动(例如动画)的信息。 骨骼(行为识别)人体通常以两种方式表达:第一是骨骼的形状。它由人类关键点和关键点之间的一系列联系组成;另一个是参数化的人类模型(例如[2] SMPL),身体姿势和轮廓的网格代表。
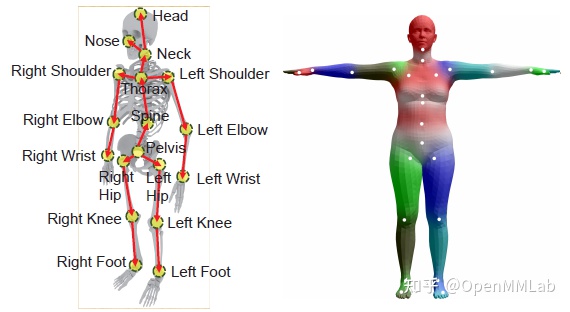
近几年,当你更多地了解 有效的人的态度估计应用,2D HPE的准确性和普遍性都大大提高了。然而,与2DHPE相比,更多的障碍等待3DHPE。一方面,收集数据是一个具有挑战性的时刻。目前,大多数方法依靠片面图片或录像。此外,将2D照片翻译为3D动议是一项多分辨率的挑战。
另一方面,深入学习算法使用了大量的培训数据。然而,由于3D动议的困难和费用,今天大多数主流数据集是在实验室收集的。这将对户外数据中算法的一般性产生影响。另外,2D HPE遇到的一些困难(例如,自我防护是3D HPE的另一个重要问题)。
这项研究将提供一些资料,介绍广泛使用的三维高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高分辨率、高档、高分辨率、高分辨率、高分辨率、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高档、高、高档、高档、高、高、高、高档、高、高、高档、高档、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、高、
1 主流算法
1.1.1 片面图像法
因为片面照片可以自由获取,且不受情景限制,输入数据有几种技术。但是,正如前面提到的,根据二维照片,三维姿势是一个令人无法接受的问题。换句话说,可能有几种三维态势。他们的二维投影 和他们的二维手势是一样的并且,一种以一目了然的图像为基础的技术也面临着自我防护、物体覆盖和深度模糊的问题。由于缺少三维数据,大多数现有办法只能使用根相对位预测。是根联合(骨架)在三个维度上的坐标。
基于一线图像的技术可分为两类,取决于是否使用了2D HPE,下文将分别讨论。
1.1.1 直接预测
这种方法不依赖于2D HPE, 3D关键点的坐标直接来自图片。典型的C2F-Vol [3] 依赖于2D HPE。
HPE Hourglas网络结构显示为3D热图,为了限制三维数据的大规模储存消耗量,采用了逐步提高深度分辨率的方法。
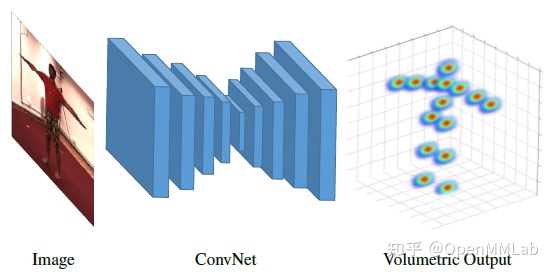
主要缺陷在于2D-3D绘图是一个非常非线性的过程,对3D空间的搜索更大,更难预测。
1.1.2 2D-to-3D Lifting
由于2DHPE非常精确和通用,作为中间阶段,许多方法使用了2D HPE。基于 2D 孔隙( 和原始图片属性) 的 3D 孔雀估计值 。一个著名的方法是3D[4] " 简单基线3D " 。该方法适用于2D关键点坐标。通过一个与碎片的全面链接,直接将2D孔隙绘制成3D空间。尽管模型非常简单,当时,算法达到了SOTA水平。研究显示,现有3D 高频动能算法的缺陷大多来自对图片信息的理解(2D HPE),而不是2D至3D寿命过程。
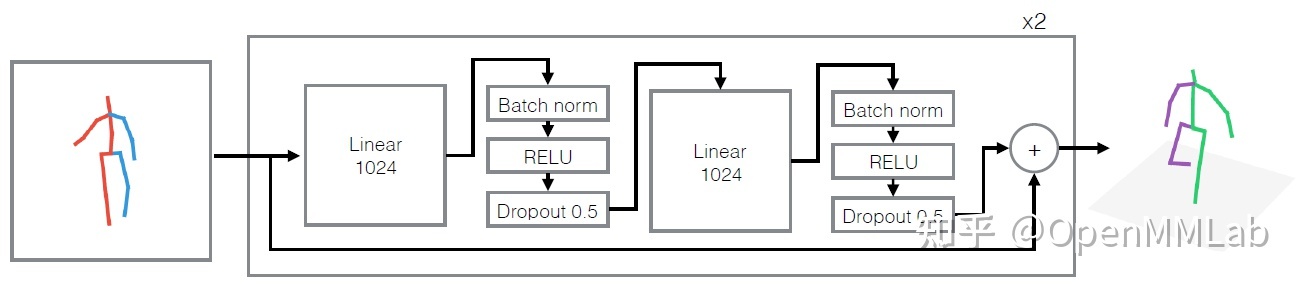
因为上述技术只是用作2D位置的一种输入,因此,2D位置的精确度至关重要。当 2D HPE 失败时,这将对随后的2D至3D生活产生重大影响。为了解决这一问题,某些算法甚至可以同时学习二维和三维运动[5]。一方面,这可以将原始图像中的信息带入2D至3D生命,从而可以用来传输原始图像中的信息。另一方面,它使培训能够结合2D/3D数据集进行。改进算法的概括化。
上述所有内容都作为一种单人技术提供,用于估计态势。在具有3D HPE的多面环境中,2D中也存在类似的问题。也可以将其归类为自上而下或自下而上。其中,自上而下的技术[10] 需要目标检测算法来确定人体的订票箱。然后,对于每一个在订票箱里的人,计算其根部的绝对坐标以及其其他接合点的相对坐标。自下而上的技术[11]首先预测了该节的位置。关节之间的相对关系然后将同一个人的关节与整个身体联系起来。" 自下而上 " 方法的主要好处是,其运行时间大多不受受检查人数的影响。在繁忙的环境中,自下而上的战略更有利。再者,自下而上的方法的关键点定位是全局性的。在装订框区域,采用了自上而下的技术。因此,自下而上的办法更适合全球信息。这样就可以在摄像坐标下更准确地定位绝对位置的人体。
1.2.2 多种子方法
为了解决遮挡问题,综合多视图信息是目前最成功的方法之一。重建一个三维位置 从一个多视角的画面,关键在于从几个角度决定如何定位现场同一地点。某些技术限制了多视角的一致性。例如,在[6]中,同时从两个不同角度输入图像。对于其中一种观点的二维位置投入,两种观点之间的过渡如下:从不同角度预测 3D 位置输出 。立体视觉公式也有一些应用。将所有角度的 2D 头映射转换为 3D 音量 。然后可通过三维滚动网络导出 3D 头图 。
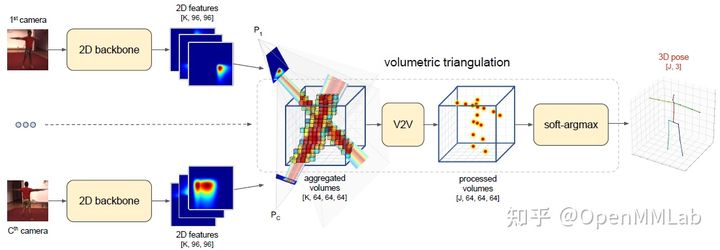
混合一些视觉图片可以帮助解决屏蔽问题,并在一定程度上解决深刻的不确定性问题,然而,这种方法对数据收集的要求更高,具有相当复杂的模型结构,在实际情况中应用有限。
一.3 录像制方法
根据这两种技术,以视频为基础的方法将提供关于时间层面的信息。相邻框架提供的背景资料有助于我们预测当前框架的态势。对于遮挡情况,根据多种姿态框架,也可以形成某些公平假设。另外,因为同一个人的骨头长度 在电影中保持不变,因此,这种做法经常对骨骼长度的统一性施加限制。有助于建立更稳定的3D职位。
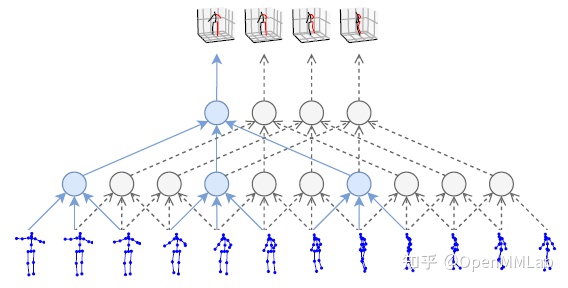
2D 孔径序列被视频Pose3D [7] 用作输入。使用时间无法初始化 Evolution 邮件组件、 进程序列信息和输出 3D 配置 。时平线上的体积是TCN的精髓。相对于区域网而言,它的主要好处是它有能力同时处理若干顺序。TCN的计算也比较简单。模型参数量较少。使用 VideoPose3D 时,提交人使用扩大的言论扩大了TCN的情绪。网络结构与简单基线 3D 结构相同。现在有一个完整的有剩余链接的音量网络。除此以外,视频Pose3D还包含基于自我审查概念的半监督培训方法。基本概念是使用轨迹预测模型预测根连接的绝对坐标。将摄像头的确切 3D 位置返回到2D飞机上这造成了重新预测的损失。半监督做法提高了3D标签有限情况下的准确性。
1.4 其他方法
这篇文章是全球之声在线特稿的一部分。3D 高能设备飞行任务中也正在使用越来越多的各种传感器。最经常使用的是深度摄像头、雷达和惯性测量仪。深摄像头和雷达提供三维空间信息这对3DHPE至关重要。它可能有助于减少或消除重大的模糊性。IMU设备可以提供有关联合指导的信息。它不依赖视觉提示。因此,它可能有助于解决屏蔽问题。
2 常用数据集
由于认识到三维重要点具有挑战性,本数据集大多得到MACP和IMU传感器的支持,因此大多数数据集仅限于室内情景。
MMPose现在支持两个最常用的3D高频个人防护设备基准,即人文3.6M和MPI-INF-3DHP,我们现在包括数据预处理脚本,使客户能够迅速收集培训所需的数据。
2.1 Human3.6M

Human3.6M现在是3DHPE问题最常用的数据集之一。它包括360万个图片框和匹配的2D/3D体动动议。数据集是在实验室环境中收集的。这部电影从四个不同角度描绘了情景,四个高分辨率摄像机同时拍摄了这些情景。MoCAP系统提供关键位置和人体共同角度的精确三维坐标。如图所示,人类3.6M具有各种各样的行动者、手势和角度。
人类3. 主要的6M评估指标是每个共同定位错误的平均值(MPJPE)和P-MPJPE。其中,欧洲所有关键点预测坐标和地面真相坐标之间的平均距离被定义为MPJPE。预测结果往往事先与实地真相的根源保持一致; 证据分析使P-MPJPE与实地真相保持一致。MPJPE应重新计算。
2.2 MPI-INF-3DHP

上面提到,尽管可获得大量数据,人类3.6M。但场景单一。为了解决这一问题,MPI-INF-3DHP增加了未来和背景的先进数据处理,从而提高了数据集中度。具体来说,其培训系列的收集工作是在绿色场景的内部使用多视相机进行的。为了获得原始数据,第一阶段是分离人体 周围环境等等然后,使用不同的纹理, 改变背景和未来。这有助于实现改进数据的目标。这套考试包括三种不同的情景。室内绿色序列、常规室内场景和户外场景都包括在内。因此,MPI-INF-3DHP更有利于评估算法的概括化。

在评价标准方面,除了 MPJPE,数据集进一步扩展了3D高专中3D高专中正确关键点和曲线下区域的使用范围,两者都经常用于2D高专中。PCK是其中不准确程度低于特定阈值(150毫米)的重要地点的比例。PCK曲线下的区域称为AUC。
2.3 CMU Panoptic

CMU 泛光[13]是一个大图数据收集系统,可用于各种目的。它从31个不同角度提供了高清晰度照片,10个不同的Kinect数据源从31个不同角度提供了高清晰度照片,10个不同的Kinect数据源提供了10个不同的Kinect数据源。它由65个视频组成(总运行时间为5.5小时)。已经创造了150多万3D骨骼。数据收集还包括若干场景。因此,这是许多人3DHPE基准之一。
3. 同样,MPJPE和P-MPJPE通常用于评估算法准确性。
MMPose 3D HPE 算法
MMPose被接受。 SimpleBaseline3D 和 VideoPose3D 这两种传统的3DHPE方法,在人3中,完成了6M和MPI-INF-3DHP数据集的培训和测试。我们还提供了基于图像和视频的选项。 demo ,如果你感兴趣,先试一试
3D HPE
这两种方法的模式结构相当相似。例如,当视频Pose3D像一个框架一样狂野时,它可能被视为视频Pose3D的具体实例。结果,我们都利用TCN作为主干。这是视频Pose3D模型 videopose3d_h36m_243frames_fullconv_supervised_cpn_ft )为例,解释如何将算法付诸实践。
3.1 Model
3.1.1 Backbone
后骨是一个 TCN 模型(见 tcn.py), 输入17个关键点的 2D 坐标, 区块总数为 4 个, 每个区块由两个有碎片连接的卷组成 。
use_stride_conv参数。论文中提到,培训阶段的模型产出限于一个单一的框架。在这种情况下,变异状态替代替代物,为了削减无谓的计算也可以产生同样的效果。实际实验中发现,利用审判谈判可以把培训时间减少一半。
3.1.2 Head
如本说明附件所述, " 负责人 " 由17个临界点的1层体积和产出三维坐标组成。 " Py.Loss " 是MPJPE错误。
3.2 Data
3.2.1 Data config
如身体3d_h36m_dataset.Py所示,以下是一些与培训数据有关的设置。
seq_len每个序列的持续时间也是模型的经验领域。temporal_padding填充两次。joint_2d_src支持三个不同的2目的来源:
3.2.2 Pipeline
数据预处理管道主要包括以下阶段(见位置3d_ transform.py):
3.3 训练配置
3.3.1 Optimizer
与条款中不同的是,最初的学习率定为1e-4,Adam被当作乐观主义者使用。
3.3.2 Learning policy
研究率采取指数下降的形式。每个时代都会失去零分 我不确定,我不确定共有200个受过训练的时代。值得注意的是,培训成套材料的原始版本包括闪光版和原始版本的所有样本。我们还使用了0的概率。5个随机翻转,为了得到一个相似的结果,我们已经把以前的时代翻了一番多了
4 总结
本条介绍了以不同方式使用的一些典型的3D高频个人防护技术和数据集。本项目是人权监察站(VideoPose3D)特别报道的一部分。MMPose提供特定的算法。其意图是,通过理解本条,你对3D HPE有基本理解,并能够阅读。我们还支持在适当的研究和应用中使用微软糖。随手star:https://github.com/open-mmlab/mmocr
更多对OpenMMLab有兴趣的人可以补充:
[社区]:1组(待补):144762544;2组:920178331
微扫瞄现在可供大众使用!

参考文献
[1] Zheng, C., Wu, W., Yang, T., Zhu, S., Chen, C., Liu, R., ... & Shah, M. (2020). Deep learning-based human pose estimation: A survey.arXiv preprint arXiv:2012.13392.
[2] Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., & Black, M. J. (2015). SMPL: A skinned multi-person linear model.ACM transactions on graphics (TOG),34(6), 1-16.
[3] Pavlakos, G., Zhou, X., Derpanis, K. G., & Daniilidis, K. (2017). Coarse-to-fine volumetric prediction for single-image 3D human pose. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 7025-7034).
[4] Martinez, J., Hossain, R., Romero, J., & Little, J. J. (2017). A simple yet effective baseline for 3d human pose estimation. InProceedings of the IEEE International Conference on Computer Vision(pp. 2640-2649).
[5] Habibie, I., Xu, W., Mehta, D., Pons-Moll, G., & Theobalt, C. (2019). In the wild human pose estimation using explicit 2d features and intermediate 3d representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 10905-10914).
[6] Chen, X., Lin, K. Y., Liu, W., Qian, C., & Lin, L. (2019). Weakly-supervised discovery of geometry-aware representation for 3d human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 10895-10904).
[7] Pavllo, D., Feichtenhofer, C., Grangier, D., & Auli, M. (2019). 3d human pose estimation in video with temporal convolutions and semi-supervised training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 7753-7762).
[8] Ionescu, C., Papava, D., Olaru, V., & Sminchisescu, C. (2013). Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments.IEEE transactions on pattern analysis and machine intelligence,36(7), 1325-1339.
[9] Mehta, D., Rhodin, H., Casas, D., Fua, P., Sotnychenko, O., Xu, W., & Theobalt, C. (2017, October). Monocular 3d human pose estimation in the wild using improved cnn supervision. In2017 international conference on 3D vision (3DV)(pp. 506-516). IEEE.
[10] Moon, G., Chang, J. Y., & Lee, K. M. (2019). Camera distance-aware top-down approach for 3d multi-person pose estimation from a single rgb image. InProceedings of the IEEE/CVF International Conference on Computer Vision(pp. 10133-10142).
[11] Fabbri, M., Lanzi, F., Calderara, S., Alletto, S., & Cucchiara, R. (2020). Compressed volumetric heatmaps for multi-person 3d pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 7204-7213).
[12] Li, S., Ke, L., Pratama, K., Tai, Y. W., Tang, C. K., & Cheng, K. T. (2020). Cascaded deep monocular 3D human pose estimation with evolutionary training data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 6173-6183).
[13] Joo, H., Liu, H., Tan, L., Gui, L., Nabbe, B., Matthews, I., ... & Sheikh, Y. (2015). Panoptic studio: A massively multiview system for social motion capture. InProceedings of the IEEE International Conference on Computer Vision(pp. 3334-3342).
本文由 在线网速测试 整理编辑,转载请注明出处。

