TCP 与 HTTP
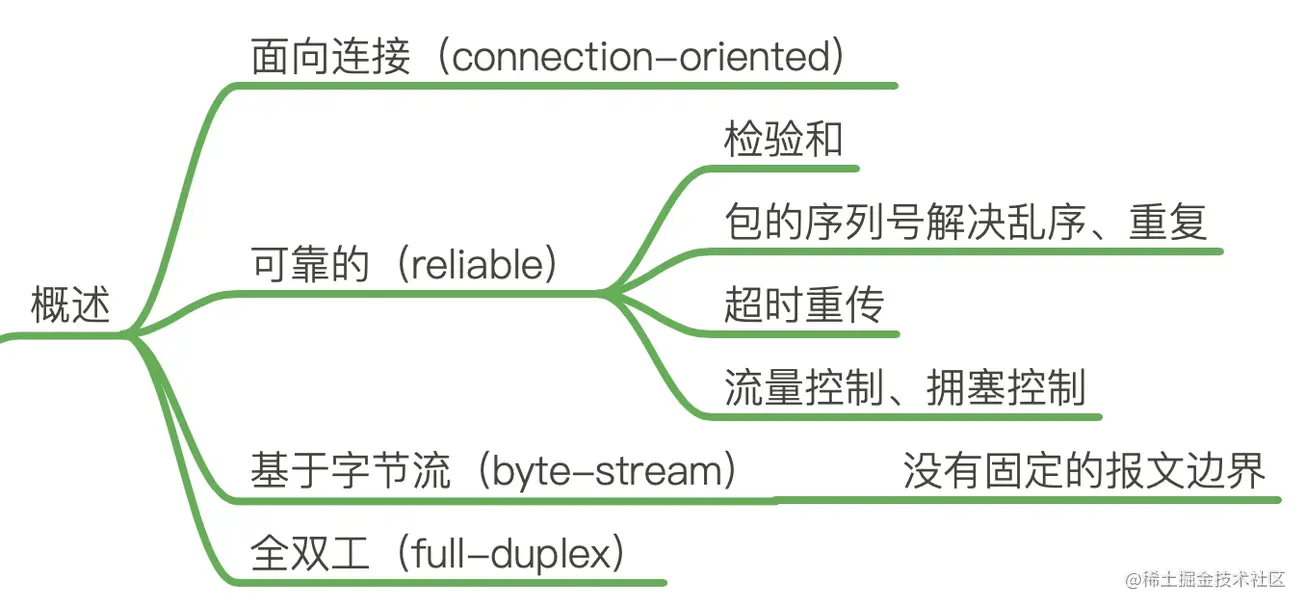
- 一、TCP
- 1、TCP协议
- UDP
- 2、TCP首部
- 1、序列号
- 初始序列号
- 2、确认号
- 3、TCP 标记
- 4. MSS(允许的TCP最高报告期)
- TCP 三号 举起三拇指
- 四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四
- 5. TCP 超时后重新发送
- 1、快重传机制
- 6. [滑窗]TCP流动控制
- 7. TCP 选区管理
- 7.1、拥塞窗口
- 7.2、慢启动
- 7.3、拥塞避免
- 7.4、快速重传
- 选择确认( SACK) 。
- 7.5、快速恢复
- 8. Nagle的算法
- 9、延迟确认
- 10. TCP的保存机制
- 二、HTTP
- 1、HTTP
- CDN
- HTTP 和 TCP 之间的连接
- DNS(域名系统)
- URI/URL
- HTTPS
- 2、协议分层
- 2.1.1. TCP/IP网络分层(四级)模式
- 2.2. OSI网络分层模型(七层)
- 2.3. TCP/IP议定书存储处的工作模式
- 3、域名(DNS)
- 域名解析
- 域名缓存
- 四,在这里插入一个链接。然后会发生什么?
- 四.1. 使用IP地址访问网络服务器。
- 四.2. 输入一个 URL 并连接到一个网络服务器。
- 5、HTTP 报文
- 五.1. 第1行(请求线,状况线)
- 5.2、头部字段
- 6. GG与POST方法之间的差异
- HTTP反应状态代码 7
- 7.1、2××
- 7.2、3××
- 7.3、4××
- 7.4、5××
- 8、HTTPS
- 8.1. 为保护保密,使用对称和对称组合。
- 8.2. 采用摘要方法确保完整性(数字摘要)。
- 8.3. 数字证书用于克服识别问题。
- TCP是一种基于IP的可靠的运输机制。IP是一种互不相连和不可信的安排。它尽可能高效率地将数据从发送者发送到目的地。然而,不能保证产品运抵的顺序与运出顺序相符。保证不复制捆绑。无法保证将一揽子货物交付给预定接受方。因此,TCP必须通过自己的程序确保自己的可靠性。从五个方面入手
- 检查每个包件的总和:在每个 TCP 包件的初始部分使用两个字节来显示校验和,并避免传输过程中的损坏。如果收到检查和不准确的报告, TCP 将不传送任何关于它被立即删除的迹象,等待发送者在发件人端重新发送。
- 包件的序号确保所收到数据的顺序和重复:TCP包件头部有32个经核实的序列号。假设我们TCP提供三个数据包由于互联网的缘故,第二包和第三包物品首先发往接收端。第一个包最后到,接收人不会因运抵和发货订单上的差异而误解装运货物。TCP重新排列其序列号,并将结果发送给顶级应用程序。如果TCP得到多余的数据也许这是因为它两次再次发送,但包没有丢失。数据将两次传送给接收者。它可以消除基于软件包序列号的重复数据。
- TCP 提供数据并开始超时 。我们正等待同侪确认收到这一数据包。如果您在规定的时限内没有得到ACK确认,就会重传数据包,然后等待更长时间,如果我们没有第一次得到它, 我们会再试一次。在多次不成功的再传送之后,TCP会交出这个包
- 流量控制:
- 拥塞控制:
- 以连接为导向:在发送数据之前,必须用“握手握手”来建立逻辑联系,而通信结束时则用一波有序的手切断连接。
- 虽然TCP在传输层传递信息,但信息可能会被破解成许多TCP信息,以便传送到网络层。 由于TCP报告不能被视为信息,TCP是一个字节流协议。
- 专职:在TCP中,传输和接收端可以是客户/服务,也可以是服务器/客户,两者都可以随时接收或发送数据,数据流可以在任何方向控制信息中单独接收或发送,如序列号、滑动窗口大小、 MSS 等。
- 并非所有袋子都贴上标签。
- 现在需要确认的不是数据集,可以推迟一段时间。
- 背包不需要自己识别,否则就会灭亡。
- 确认号总是表明收到了少于该确认号的字节。
- SYN(同步):启动数据包同步的第一个序列号。
- 使用 ACK (识别) 确认数据包 。
- RST( 重置): 此标记被用来强制断开连接, 通常当先前建立的连接不再存在, 包件是非法的, 或者我们无能为力 。
- FIN:通知另一边,我没有数据了 准备断线,我不会再寄给你了。
- PSH(普什):在收到数据包后,应传给上层。
- 数据链层传输框架的大小有限,因为一个大型包件不能直接放入链层,即“最大传输单位,MTU”。
- 如果客户因网络延迟和延迟抵达而向客户发送信息,客户此时将直接进入。
CLOSED状态。客户和原服务随后通过新的TCP连接连接。开始发送数据,这个时候,之前的报文到了,这将造成数据混乱; 等待两个MSL,当你建立了一个新的 TCP 连接,晚到的旧包裹被丢弃在网络空间里。不会干扰新的连接。 - 你用四次挥动它来关闭连接活跃的关闭党发送 最后的ACK 。如果这只船不在的话结尾处(被动百叶窗)将用后缀FIN重印。如果启动的关闭不立即将时间- WAIT 返回到关闭状态,ACK的讯息不能被怨恨因此,被动关闭方无法及时和可靠地释放。
- 当活跃的关闭方被挥动四次时, 1 MSL 用于保证最后的 ACK 信息到达正确结尾 。
- 1 MMSL 必须在结论时核实向上,没有收到回后重新传送的FIN 信号
- 慢启动
- 拥塞避免
- 快速重传
- 快速恢复
- 拥塞窗口
- 慢启动阈值
- 在三次握手之后,双方通过ACK交流各自接收窗口(rwnd)的大小,然后相互传送数据。
- 第二阶段是,每个通信都设定自己的服务对象视窗(视窗、 cwnd)的大小。
- 第3步:如果 cwnd 的起始值小于 1, 则每个 ACK, cwnd+1 和每个 RRT, cwnd 前翻倍 。
- 缓慢的开始意味着每一次的ACK, cwnd, 和RRT, cwnd, 每一次RRT时间翻一番。
- 无论间隔期间收到多少反包件,都可更加谨慎地避免伤害,每份RRT加1份。
- 将构成阈值降低到对流窗口的一半:ssthresh = cwnd/2
- Clutch 阈值指定为 Clutch 窗口 cwnd 。
- 拥塞窗口线性增加
- 您不需要等待初始数据传输。 即使是单字包也立即提供 。
- 在返回数据直至满足下列要求之一时,必须有一个累积的包件:
- MSS 数据包最大区段大小
- 收到前的包件 ACK 确认
- 如果接收器现在有数据可以发送到客户端 ACK搭便车立刻传输给客户
- 如果我们从另一个客户那里得到数据 整个时间段, 我们可以把背包组合好无数次 并立即发送出去。
- 如果在很长一段时间内没有风车,就不可能让接收站等待太久,而且必须只供应一个空袋。
- 协议的名称:“http”是指应利用对资源的利用的约定;
- 主机名:互联网主机的名字,可能是域名或IP地址,这里是“nginx”。 “来自博客Flickr网页http://ww.flickr.com/photo.org/>,根据创用CC授权使用。
- 资源在主机上的位置, 使用“ / ” 来区分等级目录, 是“ / en/ download ” 。
- ** 发送关于Ethernet和WiFi等底层网络的原始数据包,在网卡一级运作,并利用MAC地址识别网络设备,又称MAC层。
- 在这一层次上,使用了知识产权议定书。“IP地址”的概念由IP议定书界定。因此,它可能以“连接层”为基础。将 MAC 地址更改为 IP 地址 。局域网和广域网与大规模虚拟网络相连。只要“ 翻译” IP 地址到 MAC 地址, 同时查找这个网络中的设备 。
- ** 转让层:** 这一级的责任是保证数据在IP地址所查明的两个地点之间“安全地”运输,这就是TCP协议和UDP的工作水平。
- ** HTTP** 是应用层。
- 第一层是物理层,即网络的物理形式,例如电缆、光纤、网页卡、枢纽等等。
- 第二层是数据链层,与TCP/IP链接层类似。
- 第三层:网络层,类似于TCP/IP的互联网层;第四层:传输层,相当于TCP/IP的传输层;
- 5级:会议级别,保持网络连接状态,即保持通信和同步
- 第六层确定该层,并将数据转化为适当和易懂的语法和语义。
- 第七层是用于为专门应用传输数据的应用层。
- Rot DNS 服务器: 处理顶级域名服务器, 并提供顶级域名服务器的 IP 地址, 如“ com' net' cn ” ;
- 顶级 DNS 服务器: 管理各自域名下的权威域名服务器; 例如, com 顶级域名服务器可以返回 com 域名服务器的苹果. IP 地址 。
- 当局 DNS 服务器 : 维护与您域名相关的主机IP 地址, 如苹果 。 http:// ww. com/ domain_ domain_ server. comI'm not sure you're talking about what, Apple. IP address for com. com 。
- 访问根域名服务器以获取“ com” 顶级域名服务器的地址 。
- 当您访问“ com” 顶级域名服务器时, 它会告诉你“ pple ” 。 “ com 域名服务器的地址 ;
- 这是我第一次能够查阅“ww.com.com/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docss/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs
大型公司和网络运营商将建设自己的DNS服务器,作为用户DNS请求的代理商,而不是与主要的DNS系统联系的消费者。
用户访问某个网址,它不会直接发送到权限域服务器 。这是对几个“非授权域名服务器”的要求, 但它也是对一个请求的要求。他们代表"授权域名服务器" 请求它这些“非授权域名服务器”将能够在自己的缓存中发现所要求的地址。就直接返回,不再有任何要求要求“权限域名服务器 ” 。“权威域名服务器”不再受到同样多的压力。
DNS分析结果也将隐藏在操作系统中。如果你去过"ww" 我不知道你在说什么 苹果 这不是个好主意所以下一次你访问这个网站时, 你就不会去DNS询问。在操作系统中可以找到 IP 地址 。
此外,如果操作系统无法在缓存中发现 DNS 条目,它将在操作系统中查找特定的“主机地图”文件。
- 浏览器从地址栏输入中检索服务器的 IP 地址和端口号 。
- 浏览器使用三个 TCP 握手来连接服务器 。
- (a) 浏览器使用复合电文与服务器进行通信。
- 信件由服务器接收, 请求会被处理。 在将信件发送到浏览器之前, 它会拼写信件, 浏览器会分析信件并重写结果页面 。
- 访问根域名服务器以获取“ com” 顶级域名服务器的地址 。
- 当您访问“ com” 顶级域名服务器时, 它会告诉你“ pple ” 。 “ com 域名服务器的地址 ;
- 这是我第一次能够查阅“ww.com.com/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docss/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs/docs
- 开始描述所询问或答复的基本信息;
- 外地负责人收集(标题):以关键价值格式更深入地解释报告。
- 信息文本(实体):数据的实际传输,数据并非总是纯文本,但可以是照片、电影等二元数据。
- 请求方法:一个动词,如GET/POST,表示资源业务;
- (b) 请求目标:一个确定请求方法将使用的资源的URI。
- 版本号:报告使用的HTTP协议版本。
- 版本号反映了划界案中使用的HTTP议定书版本。
- 状态代码:代表治疗结果的三位数数字,例如200表示成功,而500表示服务器问题。
- 理由:在数字状态代码中增加了对语言的更广泛解释,以帮助人们理解原因。
- 获得数据,并公布提交数据。
- 获取参数有一个长度限制( 取决于浏览器和服务器, 最多为 2048 字节), 但锅参数没有限制 。
- get请求的数据会附加在url之 ,以 " ? "分割url和传输数据,多个参数用 "&"连接,而post请求会把请求的数据放在http请求体中。
- Get是直截了当的传输, 职位包含在请求中, 但可以用抓取工具观察, 与抓取工具相同, 与抓取工具相同 。
- 1x:提醒各方注意,协定目前处于中间状态,需要采取更多行动;
- 2xx: 成功收到和处理的报告;
- 3xx: 调整方向、改变资源地点、促使客户重新发送请求;
- 客户错误、请求错误和服务器故障;
- 5x: 服务器执行请求时发生服务器故障 。
- 一切都是严格保密的 只有那些不能看的人才能看
- 完整性:核实数据在传输期间没有被篡改,完整性得到维护。
- I.D.: 申明对方事实上是另一方。
最后更新:2022-05-16 11:49:13 手机定位技术交流文章
这里写目录标题
一、TCP
1、TCP协议
TCP是一个可靠、连通、字节到工作协议。当数据传输时,发送者启动定时器,如果未收到最终确认,再发送。接收端使用该序列。
UDP
TCP是一项尖端协定。我们必须首先建立连接,然后才能传输数据。它还防止数据丢失或重复。联合民主党是一个直截了当的协议。它无状态,为了交流数据,不必事先建立连接。然而,不能保证数据将发送到另一方。两项协定之间的另一个重大区别是在数据格式方面。TCP数据是一个永无止境的字节流。有先后顺序,联合民主党是一个紧凑而分散的数据集。是顺序发,乱序收。
2、TCP首部
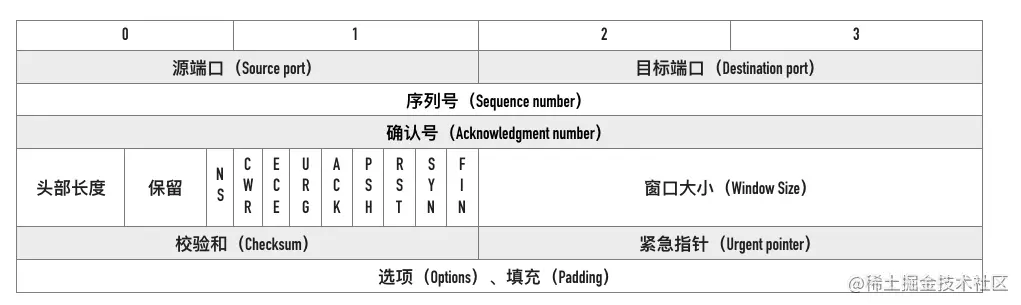
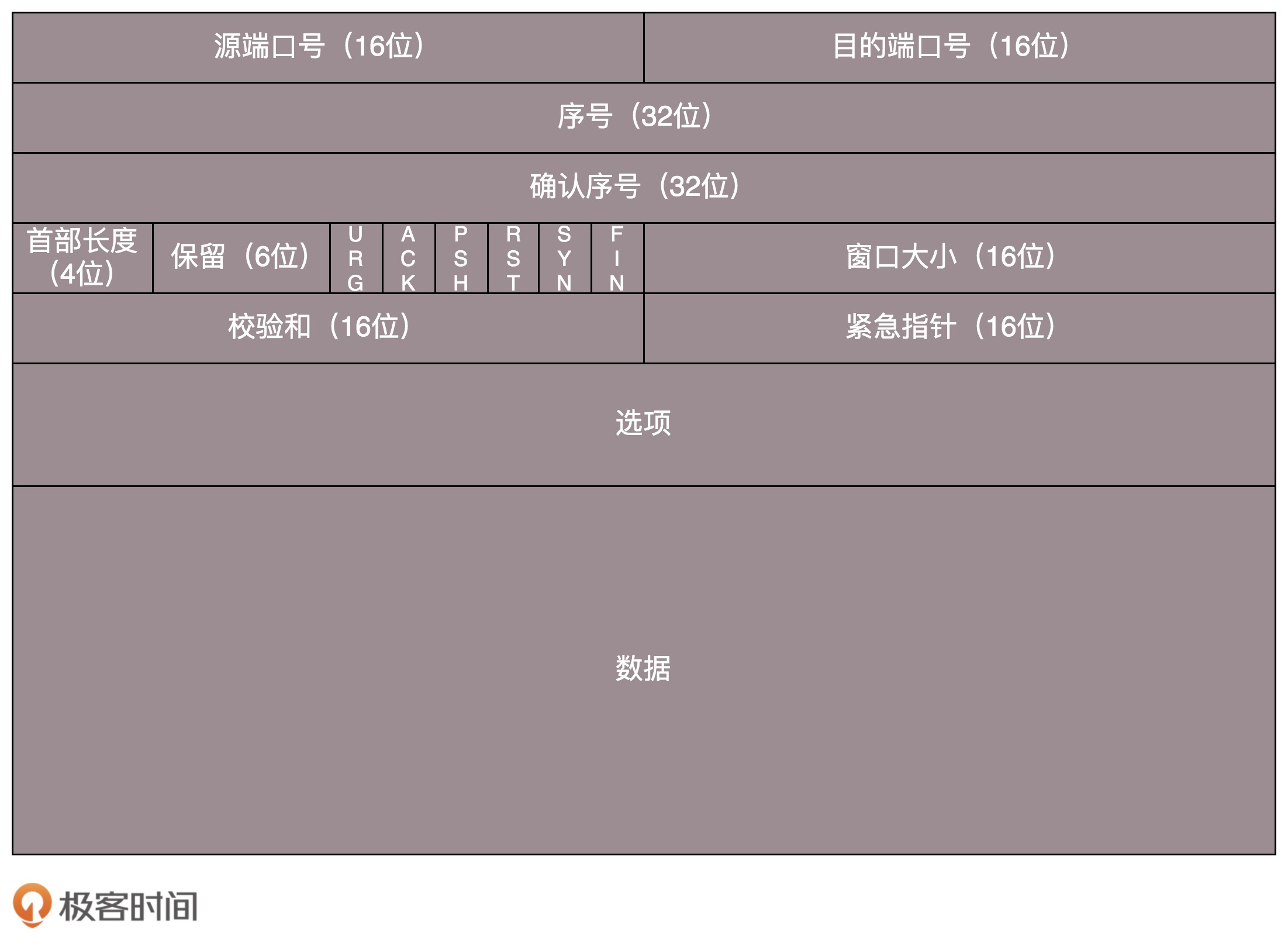
1、序列号
TCP是一个字节流协议,为通过TCP传送的每个字节流分配序号,序号与本报告字段的第一个字节对应。

序列号加上电文长度,使您能够区分数据中哪个部分是递送的。序列号为32位数的无符号整数,在回收到 0之前可超过232-1。
SYN电文中使用序列号交换对方的初始序列号;在其他报告中,序列号用于订购包件;在其他报告中,序列号用于订购包件。
由于网络层(IP层)不能保证软件包顺序,TCP协议使用序列号来克服网络包装和重复的问题,并确保软件包按正确的顺序发送到上层。
初始序列号
每个来文方在连接开始时选择一个序号,称为初始序号,在连接确定后,双方通过SYN报告交换其初始序号。
第一个序列号由MD5使用源地址、目标地址、源端口、目标端口和随机系数生成。因为我们的MD5是一个数学算法如果只有这些变量存在,在现实中,第一个序列几乎肯定是一样的。所以我们只是在MD5计算中加入时间变量。因此,第一批序列号不再重复。
2、确认号
TCP使用确认号(ACK)通知另一方,所有低于该确认号的字节均已收到。
3、TCP 标记
TCP包含几种不同类型的标签,其中一些用于开始初始序列号同步化,另一些用于验证数据包,还有一些用于停止连接。 TCP提供了一个8位元字段用于标记旗帜,主要在6个字符之后使用。
我们使用SYN、ACK、FIN和RST等词时, 基本上只是与所设定的拖线相对应的比特。 这些标记可以合并, 例如 SYN+ACK、FIN+ACK等等 。
4. MSS(允许的TCP最高报告期)
为防止向分隔器转移,TCP主动将数据分成小部分,然后将其传送到网络层,其中最大的一层称为管理支助系统。
AMWS的数据可能适合没有段段的 MTU。
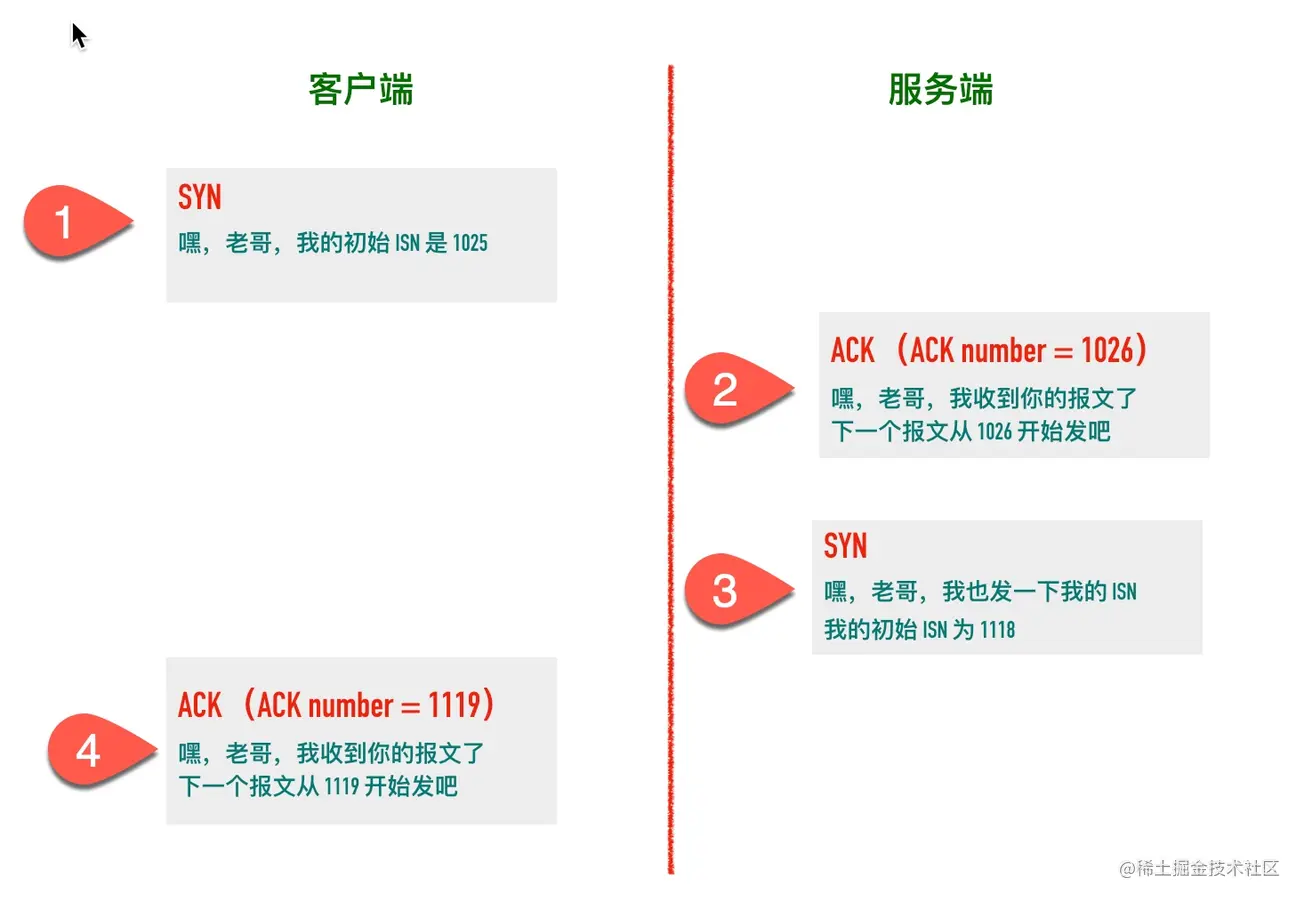
TCP 三号 举起三拇指
这三次握手是为了交换客户和服务处的第一个序列号。
第一次握手:
客户将先确定初始序列号,然后将SYN信息发送到服务处,在服务处有SYN标记,SYN信息包含我们的第一个序列号,第一次握手将用来保留客户初始序列号的服务。
SYN电文不包括数据,但必须加以验证,因此将使用一个序号,并在下次发送时添加一个序号。
第二次握手:
该服务还将获得初始序号。然后客户会收到SYN和ACK留言SYN信息的目的是将服务的第一个序列号告知客户;ACK信息的目的是通知客户,我收到你的SYN留言了您的下一个消息将从 SYN 的 +1 序列号开始 。
因为ACK报告不包含任何数据,也不需要确认, 它并不消耗序列号。 你只需要一个序列号。 在他完成后, 他可能会继续下一个序列号 。
第三次握手:
客户收到服务发送的SYN信息后,即向客户发送ACK信息。
四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四、四
第一次挥手:
客户端会发送 FIN 消息给服务器 。FIN的责任是相互通报。我发完了所有数据,准备断开连接,我不会再给你寄数据包了事实上,FIN信息将FIN的标识设置为1。这篇文章是全球之声在线特稿的一部分。用户不再能够向服务器提交数据 。您可获取服务端数据。
FIN信息可以通过数据传递,客户在传输最后一份数据时可以带来,或者在没有数据的情况下消费,并且会消耗一个序列号。
第二次挥手:
当服务器从客户端收到 FIN 信息时, 它会向客户端发送 ACK 信息, 表示它知道你会关闭它 。
第三次挥手:
如果服务器没有任何数据可供提供,它会向客户端发送FIN信息,等待客户端确认。
第四次挥手:
收到服务发送的FIN信息后,回复 ACK 信息,在步骤三中确认 FIN 信息,输入。TIME_WAIT等待以下两个MSL 输入CLOSED输入后,服务器收到一个ACK。CLOSED状态。
MSL:
MSL是TCP报告在网络中生活的最大时间。
我们为何要等两个MSL/Time_waits的存在,以便:
为什么有两个MSL?
5. TCP 超时后重新发送
TCP传输数据,同时启动定时器。我们正等待同侪确认收到这一数据包。如果您在规定的时限内没有得到ACK确认,就会重传数据包,然后等待更长时间,如果我们没有第一次得到它, 我们会再试一次。在多次不成功的再传送之后,TCP会交出这个包
1、快重传机制
当发件人收到三次或三次以上的重复,ACK怀疑上一个包裹丢失,并迅速重新发送。
6. [滑窗]TCP流动控制
流程处理防止将端到端数据传送给收到过多的接收者。
滑动窗口的功能是接收缓冲区空闲空间,接收端将通过ACK包将窗口大小通知传输方,发送方将发送基于窗口大小的数据,用于交通管理。
TCP 将存储在发送缓存中传输的数据,在接收缓存中接收数据,并继续读取接收缓存以供处理。
如果缓冲区满载,发送者应停止发送数据;为了管理发送者的速度,接收部门将通过作为缓冲自由部分的ACK软件包通知客户自己的接收窗口,发送者将修改其发送策略以达到此值。
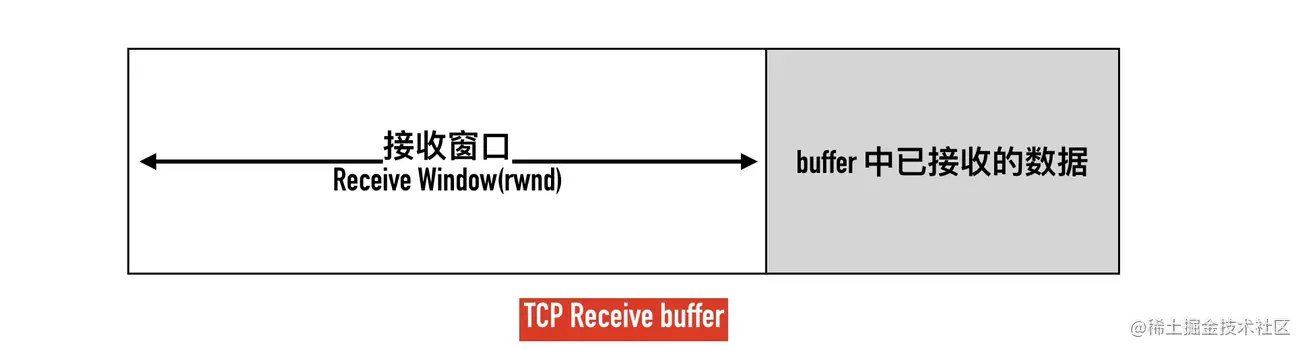
ACK 包将接收端窗口的大小通知发件人,例如, 赢= 3,00; 发件人得到这个 ACK 软件包, 并将其发件人窗口限制为3,00。 如果赢值等于零, 发件人应停止发送数据 。
7. TCP 选区管理
流程处理只是抑制数据从发送端到接收端的传输,同时考虑到整个网络的通信状况,因此需要对浓缩进行控制,这限制了网络一级的数据传输。
涉及四种算法:
为了实施上述技术,每个TCP连接都保留两个值:
浓缩控件是指控制压缩窗口移动的四种算法。
7.1、拥塞窗口
压缩控制窗口的大小取决于网络的凝结程度和动态变化。发送者将自己的发送窗口移动到凝结窗口中一个较小的接收窗口,接收者将自己的接收窗口移动。
如果接收窗口小于持有窗口,接收终端处理能力就不足。如果压缩窗口小于接收窗口,接收终端处理能力就足够,但网络超载。
凝结控制算法的精髓是调节 cwnd 的变化。
7.2、慢启动
发送者不知道接收端在TCP连接开始时的速度有多快,如果是一个缓慢的网络,在某一端传送大量数据可能会增加网络延误。
结果,每个TCP连接都有一个压缩的窗口限制,其初始价值很小,整个价值很小,这种技术被称为每次提供数据时缓慢启动。
算法的逐步开始如下:
TCP 在发送时记录该包件 t1 的交付时间, 接收时记录 t2 减 t1 。
压缩窗口的大小不能增加。 我们通过逐步引入阈值来调节它。 当压缩窗口小于慢启动阈值时, 它会以指数方式扩张; 当压缩窗口大于慢启动阈值时, 它会直线增长 。
7.3、拥塞避免
当我们的浓缩窗口超过缓慢的起始阈值时,即启动冷凝避免阶段,在发现冷凝之前,每次增加一个管理支助系统;管理支助系统是TCP允许的最大报告期间。
与慢启动的区别在于
7.4、快速重传
从首次传输数百毫秒的再传输到再次传输之间的时间,TCP将利用计时器请求中止传输。在中止期内,没有交付新的或重复的数据包。
当接收者收到一个不规则抵达的数据段时,TCP立即发送重复的ACK,当发送者收到三个或三个以上重复的ACK时,它得出结论,上述包件可能已经丢失,并很快重新发送,而没有愚蠢的等待再发送定时器。
选择确认( SACK) 。
迅速的再传送解决了问题,但也引入了一个新的问题:丢失的包件有可能丢失,无论是否重新传送,以及确认它解决了这一问题的备选办法。
选择显示在发送复制的 ACK 软件包时, 接收端将跟随接收的软件包返回发件人, 告知发送方接收端已收到后续软件包, 只有丢失的软件包才会重新发送 。
7.5、快速恢复
当连续三次收到ACK时,网络进入快速恢复阶段,这可被视为轻网络堵塞。
8. Nagle的算法
Nagle方法旨在尽量减少发件人向收件人分发的传单数目。
在发件人端,发件人端使用Nagle算法简而言之:
Nagle方法可以减少发送小包件的频率,将小包件合并,但以略为延迟为代价。
此外,在延迟确认的同时使用Nagle算法也存在重大性能问题,Nagle一次储存并传送一次,袋装接收确认延迟,没有及时返回。
9、延迟确认
如果在接收数据包后目前没有向对方分发数据,则无法相互发送数据,如果在接收数据包后没有向对方分发数据,则在接收数据包后暂不向对方发送数据,则无法相互发送数据。验证(Linux上40米)可能需要一些时间。如果信息被发送 正确的人此时,ACK可能和数据一起发送如果没有在时限内提交数据,也发送 ACK,以免以为对方丢了包。这个方法被称为"延迟确认"
因此,对空的ACK的回答,就像Nagle算法一样,是浪费时间。
这一过程被称为延迟确认。
10. TCP的保存机制
网络或系统故障将使得很难获得这一信息直至完成。如果程序无法传输数据,连接可能不再有效。假设应用程序是一个网络服务器。客户使机器失灵,或在三次握手后被赶出网络。仅供网络服务器使用。以下数据包将永不公布。但是它一无所知
保存机制由TCP协议设计者建立,以回应对长期死亡连接进行此类测试的必要性。
二、HTTP
1、HTTP
HTTP是超文本传输协议的缩略语。我们就关于电子通信的规则达成了协议。有几种管理和处理不当的方法。实际上,通信就是传递信息。由于TCP是一个二进制包件,它不传输数据。HTTP 发送浏览器服务器可以处理的完整相关数据 。比如我们的HTML
HTTP常常在TCP/IP堆叠上操作,IP协议用于定位和路线安排,TCP协议用于可靠的数据传输,DNS协议用于域名查询,SSL/TLS协议用于安全通信。
CDN
浏览器没有声明它直接连接到服务器, 中间有一个 CDN, 主要是缓存加速 。
CDN可以从源站缓存数据, 这样浏览器的要求不会“ 千里之外”, 答案会直接从“ 半途” 获得 。
HTTP 和 TCP 之间的连接
TCP是一种传输控制协议,以IP协议为基础,使可靠的字节流通信形式成为可能,它是HTTP的基础,它不担心传输的具体细节,而是按照TCP协议运作。
TCP是用于特定数据传输的HTTP子级别协议。
DNS(域名系统)
为了在 TCP/IP 协议中识别机器, 请使用 IP 地址 。 计算机可以很容易地回忆数字地址, 但数字很难记住 。
DNS 以有意义的名称取代IP地址的数量。 它被称为域名 。
然而,要小心,我们使用 TCP/IP 协议与IP 地址互动, 我们必须将域名“ 映射 ” 转换为其真正的 IP 地址, 这个过程被称为“ 域名解析 ” 。
URI/URL
DNS 和 IP 地址仅识别互联网上的主机,但主机包含许多文本、图像和页面,因此我们需要使用 URI (统一资源标识符) 来识别互联网上的唯一资源。
联合资源定位器(URL)在技术上是URI的子集,但由于两者几乎相似,区别较小,通常没有严格的区分。
URI由三个主要部分组成:
HTTPS
HTTPS是“HTTP+SSL/TLS+TCP/IP”的缩略语,有 HTTP的安全外壳。
2、协议分层
2.1.1. TCP/IP网络分层(四级)模式
框架是MAC层的传输装置包是一个IP层运输装置。一个小段传输 TCP 层 。HTTP的传输装置是信息或信息(信息)。然而,这些区别是毫无意义的。可以统称为数据包。
2.2. OSI网络分层模型(七层)
2.3. TCP/IP议定书存储处的工作模式
使用 TCP/IP 协议仓库的HTTP 数据传输可被视为一种交付程序。
假设你给同学送快递,你就会把事情打包起来, 这就是HTTP会传送的东西, 就像HTML一样, 它会像HTTP协议一样被包起来, 并有一个独特的 HTTP附件。
然后交给快递员,他向快递员提供一个装有快递标志的盒子,相当于将数据再次包装在TCP地板上,包括TCP头部。
随后将快递送到分发点,放在更大的卡车上,即IP头的TCP对口机,IP、MAC和TCP数据包上的MAC头。
当您到达另一个城市时,您必须卸载货物,即IP层和MAC层转移后的货物包。
信使到达你朋友的门, 摘下标签, 摘掉TCP层的头, 塑料袋包装, HTTP层的头, 最后的玩具, 真正的 HTML 页面。
3、域名(DNS)
为了在 TCP/IP 协议中识别机器, 请使用 IP 地址 。 计算机可以很容易地回忆数字地址, 但数字很难记住 。
DNS 以有意义的名称取代IP地址的数量。 它被称为域名 。
然而,要小心,我们使用 TCP/IP 协议与IP 地址互动, 我们必须将域名“ 映射 ” 转换为其真正的 IP 地址, 这个过程被称为“ 域名解析 ” 。
域名解析
DNS核心系统是三级基于树的分布式服务,基本域名结构如下:
比如说,你要去“ww.org”。我不知道你在说什么,苹果。下面问三个问题:
域名缓存
四,在这里插入一个链接。然后会发生什么?
四.1. 使用IP地址访问网络服务器。
四.2. 输入一个 URL 并连接到一个网络服务器。
浏览器将首先检查您提供的 IP 地址是否有效 。否则,将处理域名。看看是否有浏览器自己的缓存如果您的操作系统没有缓存,我们尚未审查主机域名文件。发送 HTTP 请求创建TPCP 连接, 如果有的话 。
如果不是, 请尝试根域名、 顶层域名和权限域名图层来搜索 。
比如说,你要去“ww.org”。我不知道你在说什么,苹果。下面问三个问题:
解析失败, 因为浏览器试图更改另一个 DNS 服务器, 最终无法输入正确的页面 。
5、HTTP 报文
对HTTP协议的请求和答复具有相同的基本形式,包括三个主要部分:
在前导句和电文中,前两条常被称作“请求头”或“回应头”,但“实体”却与“标题”相关,并经常被直接称为“机构”。
HTTP协议希望听到信息,但没有机构。
五.1. 第1行(请求线,状况线)
请求行是请求的第一行。
请求项目分为三节:
(a) 对报告第一行和州一行的答复;
状态线分为三节:
5.2、头部字段
在HTTP报告中,请求行或状况线以及外地总人才库代表了整个请求或回应主管。
页眉字段使用键值对比结构。带有“ : ” 的独立的键和值此字段由 CRLF 的换行符终止 。例如,“住家:”一行的关键是“住家”。"价值"是"价值"的缩写
6. GG与POST方法之间的差异
虽然HTTP协议可能导致在使用上出现差异(基本上相同),但获得和职位基本上属于TCP连接,实际上HTTP协议可能导致在使用上出现差异(基本上相同),获得和职位基本上属于TCP连接。
** 区别在于 **get 在请求时提供数据包, 并同时发送信头和数据, 而**poot 生成两个数据包, 首先是发送信头, 服务器返回100, 然后传输数据, 服务器返回200 。
HTTP反应状态代码 7
状态代码代表 HTTP 数据处理的“ 状态 ”, 客户端可以使用它来选择下一步动作 。
大体分为五类:
7.1、2××
2 x 类状态代码显示服务器接收和处理的客户请求正确无误。
最常成功的国家代码是“200OK”, 这表明一切都很好。
7.2、3××
3 x 类状态代码显示客户要求的资源已经改变, 客户必须用新的 URI 重新配置资源, 通常被称为“ 转划 ” 。
“301 永久永久调整方向”表示所请求的资源不再可用,需要一个新的资源研究所再次访问。
“302 发现暂时重新定向”,所请求的资源仍然可用,但必须临时使用另一资源来获取这些资源。
7.3、4××
4xx类身份代码表明客户的要求不正确,服务器无法处理。
“400坏请求”是一个相当宽泛的错误代码,没有提及特定问题。
“403禁止”信息表示服务器禁止访问资源。
无法在此服务器上找到资源“ 404 找不到”, 无法发送到客户端 。
7.4、5××
5 x 类状态代码显示客户的请求是正确的, 但服务器在处理中遇到内部问题, 无法提供合适的响应数据, 即服务器的“ 错误代码 ” 。
一个典型的错误代码是“500国际服务器错误 ” 。
8、HTTPS
由于HTTP是一个明确的通信协议,整个传输过程是完全可见的,任何人都可以在链接/对报告的答复中拦截、编辑或伪造请求,使数据不可信。
HTTPS 将 HTTP 子级别协议修改为 SSL/ TLS, 允许 HTTP 在安全的 SSL/ TLS 协议上运行, 这相当于在应用程序和传输级别之间设置 TLS 安全级别。
HTTP 三个级别的安全级别:
8.1. 为保护保密,使用对称和对称组合。
对称加密
同一密钥用于加密和解密对称加密。 密钥必须安全。 对称加密的问题是确保密钥的安全传输 。
非对称加密
非对称加密使用两把钥匙,一个公用钥匙和一个私人钥匙。 公用钥匙可以免费使用,而私人钥匙必须完全隐藏。
私有密钥只能解码公用密钥加密,而公用密钥只能解密私用密钥加密。
非对称加密是一个艰难的数学问题,基于大数字的计算,如大量质数或椭圆曲线,因此消费是计算慢体数加密,而根据大数字的计算,如大量质数或椭圆曲线,消费是缓慢计算的。
我们使用非对称加密发送对称加密密钥,然后加密。
8.2. 采用摘要方法确保完整性(数字摘要)。
如果黑客得不到会话钥匙 他们就能利用它无法破解密文,另一方面,偷听可以提供足够多的秘密。我们试图更新和重组它,然后上传到网站。没有诚实的保证。服务器只能接收“ 所有副本 ” 。然后,服务器的答复将向他提供进一步的信息。它最终会被解密
Hashi 算法是抽象算法,它绘制了输入一定输出长度(例如MD5)的输入长度。
我们将对称加密密钥, 然后将摘要附加在它上, 然后在公用密钥中加密。 这被称为数字摘要 。
8.3. 数字证书用于克服识别问题。
这也是关于信任一个公用钥匙 黑客可以用来上传
目前,我们必须利用CA来解决公共关键信任问题。
小CA允许大CA的签名认证,直到根CA到达。
证书撤销的问题
本文由 在线网速测试 整理编辑,转载请注明出处。

