【Mixup】《Mixup:Beyond Empirical Risk Minimization》
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 5 Experiments
- 5.1 Datasets and Metrics
- 5.2 Experiments
- 6 Conclusion(own) / Future work
- 记住(而不是从)训练数据
- trained with ERM change their predictions drastically when evaluated on examples just outside the training distribution,也被称为敌对的例子泛化性能不够)
- reduces the memorization of corrupt labels
- increases the robustness to adversarial examples
- stabilizes the training of generative adversarial networks(GAN)
- 提高口语和口语的一般化
- 混合效应持续超过2小时,但计算成本增加
- 混合的两张照片来自同样的小型批量,省了I/O
- 仅对相同的标签的混合效果没有显著提高(单类混合的效果不是显而易见吗?)
- CIFAR-10 / CIFAR-100
- ImageNet
- UCI
- the Google commands dataset
- top1-error
- top5-error
- 白盒攻击:可以获取攻击模型的模型参数;
- 黑箱攻击: 攻击的模型参数无法获得.
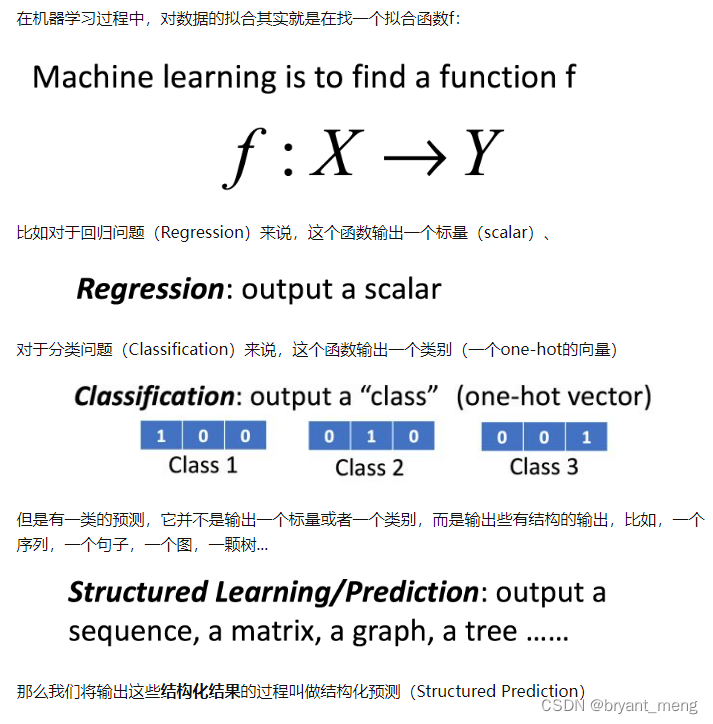
- 用于回归和结构学习(例如分裂)
- 用于半监督 、 非监督和深入强化学习.
最后更新:2022-07-01 18:28:57 手机定位技术交流文章

ICLR-2018
文章目录
1 Background and Motivation
当前的模式正变得更加强大,但记忆和对敌对的例子的敏感性还不够。
作者从Vicinal Risk Minimization (VRM) principle首先,我们提出了一种混合数据增强方法(convex combinations of pairs of examples and their labels)加强现有的SOTA模型的推广能力
问:VRM是什么?Empirical Risk Minimization (ERM)开始说
简单来说,做机器学习任务时,我们不能得到数据的真正分布(例如猫和狗分类,世界上的猫狗数量是无穷的),所以我们不能尽量减少真正的风险,在训练数据上尽量减少他们的平均误差,也即最小化经验风险
[数学知识] 尽量减少经验风险和结构风险

the convergence of ERM is guaranteed as long as the size of the learning machine does not increase with the number of training data.
当数据确定时,模型的规模越大,对基于EMR原则训练的模型的问题就越大:
模型大了,与数据量不匹配,经常需要从实际分布中获得多个采样点,换句话说,我们正面临着越来越多的数据方法,这种方法经常在重叠时被使用,formalized by the Vicinal Risk Minimization (VRM) principle
具体的,
作者提出了一种新的数据扩充、混合方法
2 Related Work
略
3 Advantages / Contributions
提出了一种混合数据增强方法(详细介绍),improves the generalization of state-of-the-art neural network architectures
4 Method
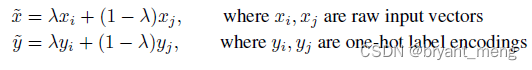
其中 λ ∼ B e t a ( α , α ) lambda sim Beta(alpha, alpha) λ ∼ B e t a ( α , α )
code
B
e
t
a
(
α
,
β
)
Beta(alpha, beta)
B
e
t
a
(
α
,
β
)
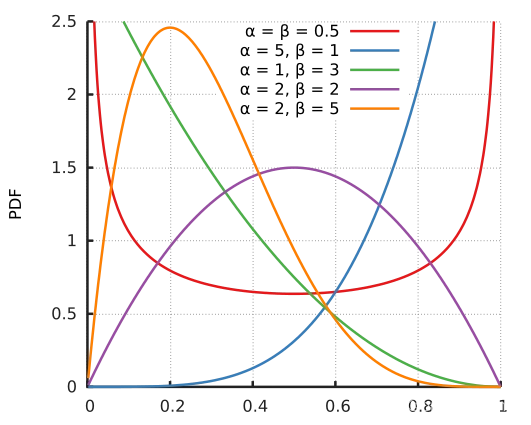
分布的概率密度函数如下:
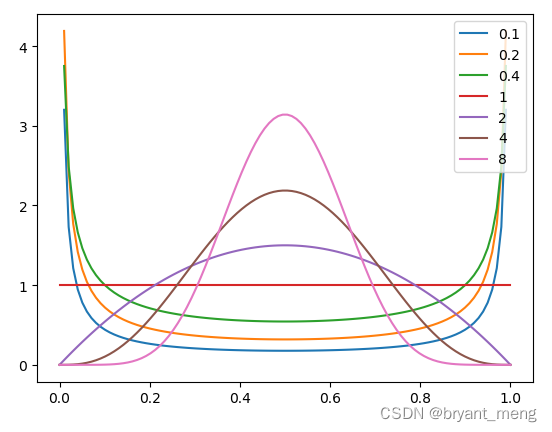
本文
α
=
β
alpha = beta
α
=
β
下面是一些出现的文本 α alpha α 图像
部分代码
你可以看到概率密度函数是对称的. α = 1 alpha=1 α = 1 时, B e t a ( α , α ) Beta(alpha, alpha) B e t a ( α , α ) 成了均匀分布
当 α → 0 alpha rightarrow 0 α → 0 在采样时,β的概率密度函数倾向于为0 λ → 0 lambda rightarrow 0 λ → 0 没有混合融合,VRM返回ERM
当 α → ∞ alpha rightarrow infty α → ∞ 贝塔的概率密度函数倾向于 ∞ infty ∞
作者发现
What is mixup doing?
encourages the model f f f to behave linearly in-between training examples尤其是在不同的类中,以前的数据扩展是基于相同的类,混合引入了不同的类之间的关系的先驱,尽管它是最简单的线性关系。
mixup leads to decision boundaries thattransition linearlyfrom class to class,providing a smoother estimate of uncertainty

5 Experiments
5.1 Datasets and Metrics
数据集
评价指标
5.2 Experiments
1)ImageNet Classification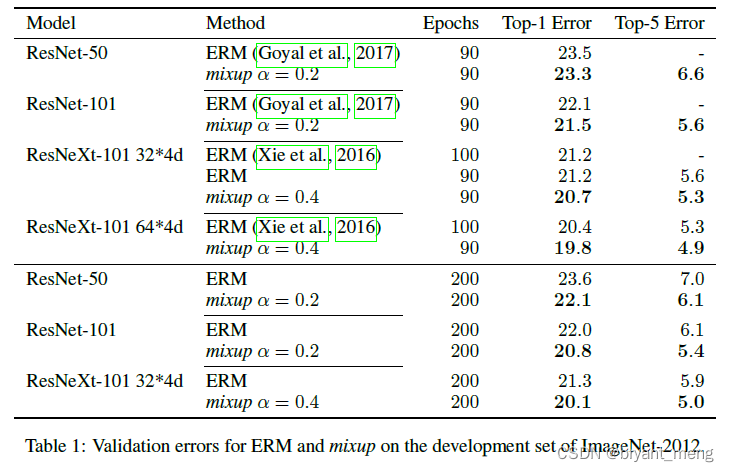
α
∈
alpha in
α
∈
[0.1,0.当混合比EMM更好时,对大
α
alpha
α
, mixup leads to underfitting(
α
alpha
α
越大
λ
lambda
λ
我们越倾向于得到0.5,两幅照片的重叠越深,原始数据越远,匹配的难度越大)
模型越大,训练时间越长,混合物的作用越明显
2)CIFAR-10 and CIFAR-100
α
alpha
α
设置为1,β分布现在与均匀分布相等,即:
λ
lambda
λ
任何从0到1的值的概率是相同的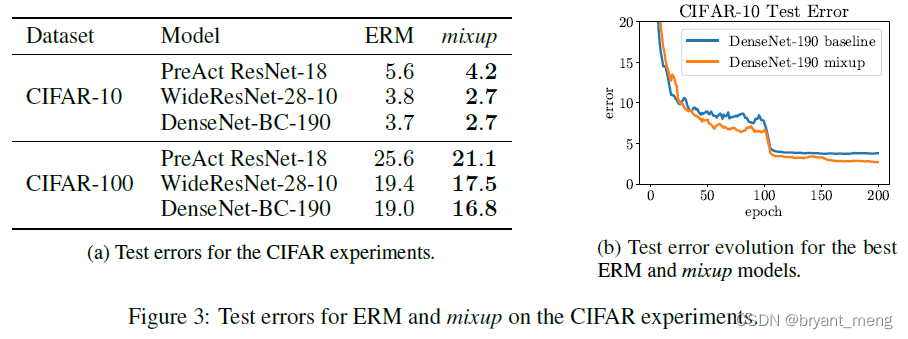
3)Speech data
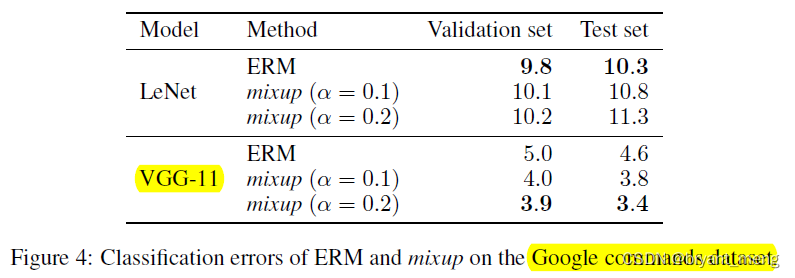
LeNet没有ERM好的,VGG比ERM更好
4)Memorization of corrupted labels
CIFAR-10数据集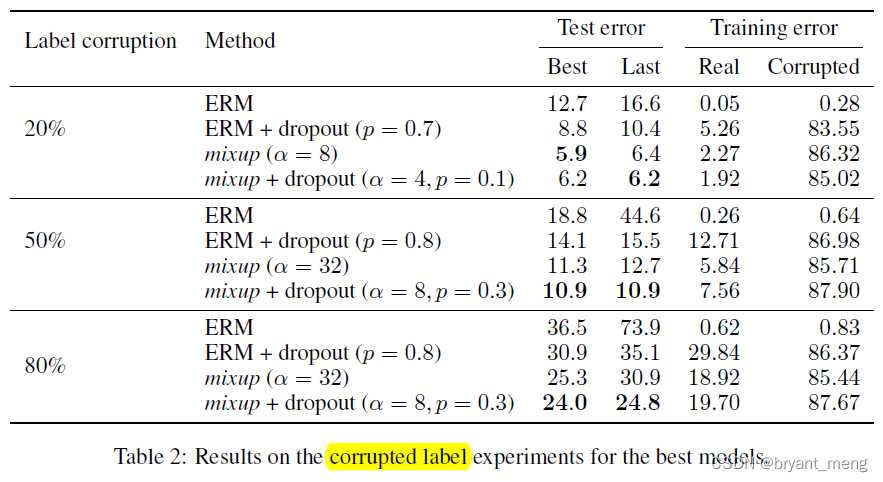
α
alpha
α
混合的越大,融合的深度越深,使记忆变得更加困难
显然,没有混淆,非常严重的过度匹配,学习了所有的错误信息(尤其是在损坏数据集上的低训练错误)
如何评价混合物: 超越职业风险的最小化?
混血和流离失所也会相互促进
5)Robustness to adversarival examples
ImageNet
惩罚损失梯度的标准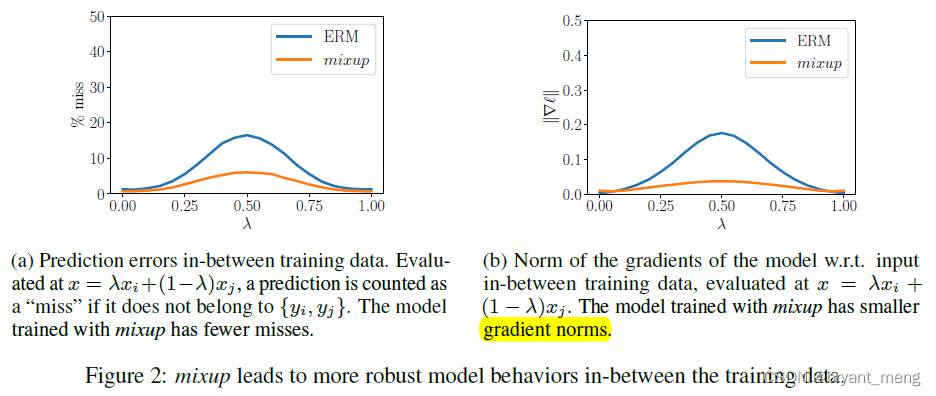
你可以看到混合物的梯度图案较小
让我们看看下面的样品反击的效果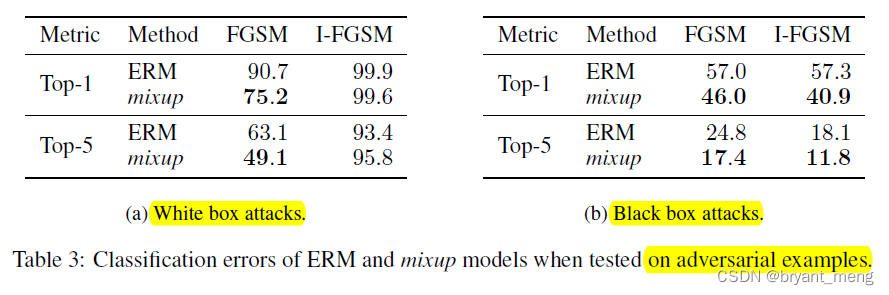
显然,混合物有很多好处
白箱攻击和黑箱攻击:
fast gradient sign method(FGSM)
以下关于FGSM的介绍和代码来自: 打击FGSM模型

6)Tabular data
使用UCI机器学习数据集,表格表格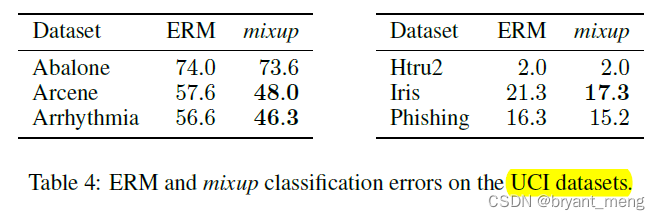
7)Stabilization of GAN
GAN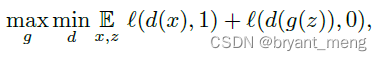
GAN + mixup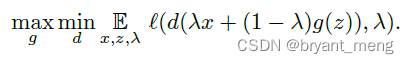

模拟两套玩具数据集(蓝色样品)时,混合GAN(橙色样品)训练的稳定效果。
Mixup + GAN更稳定
8)Ablation studies
探索混合物的不同形式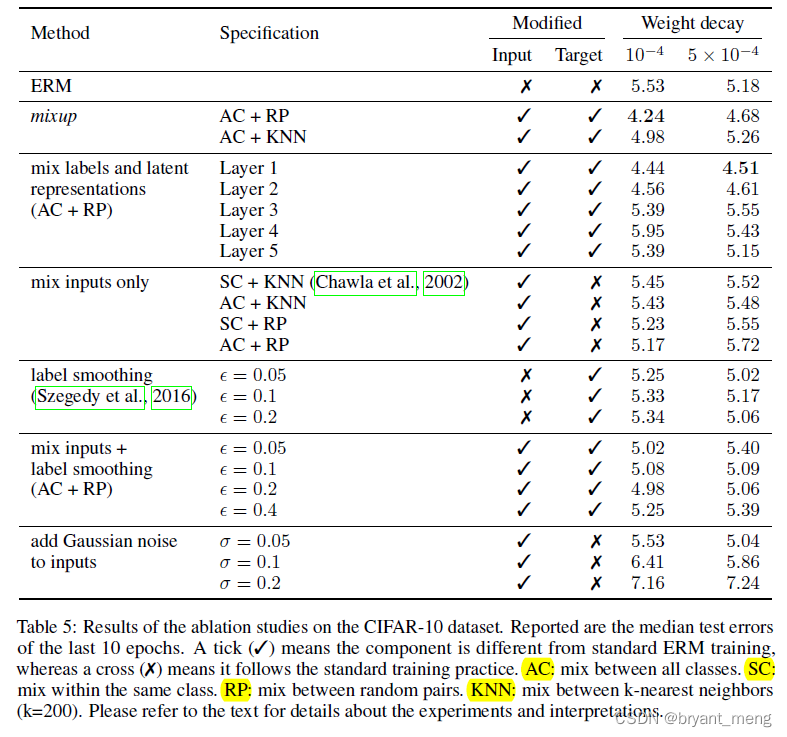
ERM a large weight decay works better, whereas for mixup a small weight decay is preferred
9)Discussion
increasingly large α alpha α the training error on real data increases, while the generalization gap decreases.
increasing the model capacity would make training error less sensitive to large α alpha α
6 Conclusion(own) / Future work
1)未来工作:
2)源码
https://github.com/facebookresearch/mixup-cifar10/blob/main/train.py
最完整的网络是Mosiac, MixUp, CutMix等。


所以当你有更多的类别的数据集时,区分一些困难的案例可能很有效,但并非所有案例都可以混在一起,至少在一个类别,我认为这并不十分有效。
数学积分结果的本质是什么?

如何理解β分布一般? - 马的学生回答 - 我知道

Beta分布具有共轭优先权的性质,即:
且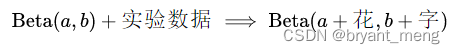
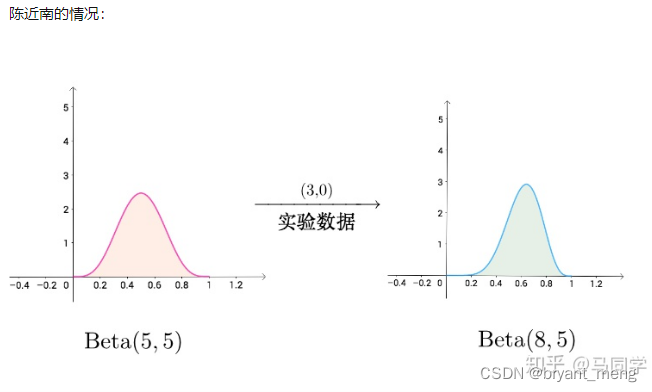
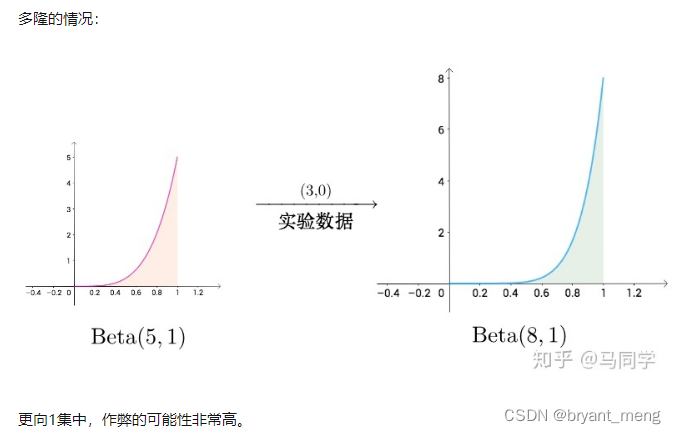
6)正常分布概率密度分布函数的纵向坐标值是否大于1?
7)结构预测
8) 如何评价混合物: 超越职业风险的最小化?
这些综合训练数据的作用,广为人知的解释是“增强模型对特定变换的不变性”。这句话反过来说,在机器学习中,它经常被称作“减少模型估计的差异”,它控制了模型的复杂性。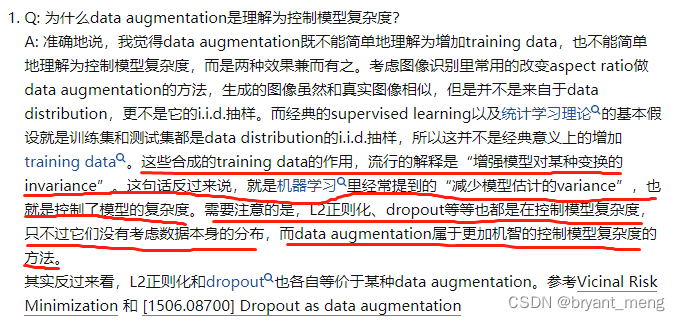
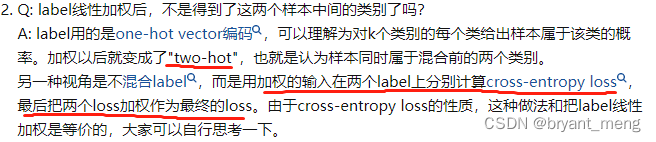

9)如何评价混合物:在职业风险的最小化之外?-张兴周的回答
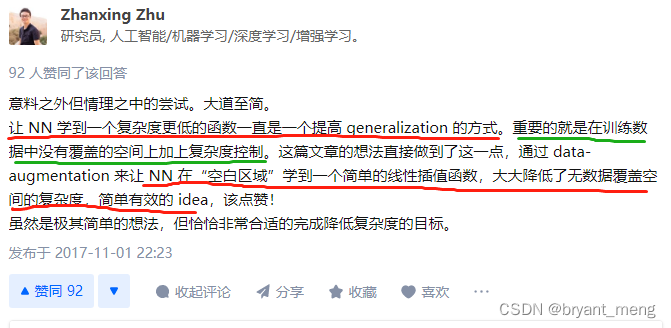
10)标签平滑,混合理解

11)为什么混合使用β分配?
视角1: miksup为什么应该使用β发行?- Sincere's Answer
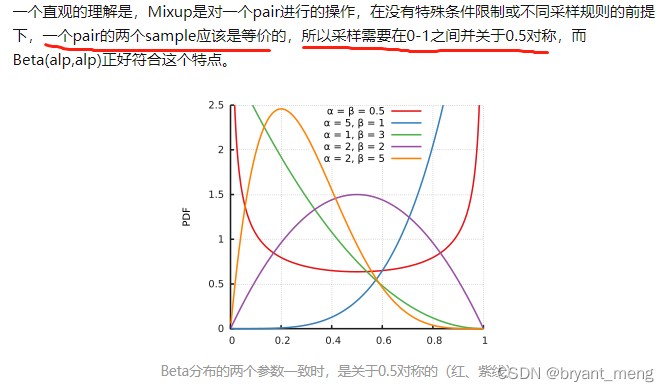
展望2: miksup为什么使用β分配?-周瑜亮的回答

回答是大igo的!
12)β分布样本混淆
如何评价混合物: 超越职业风险的最小化?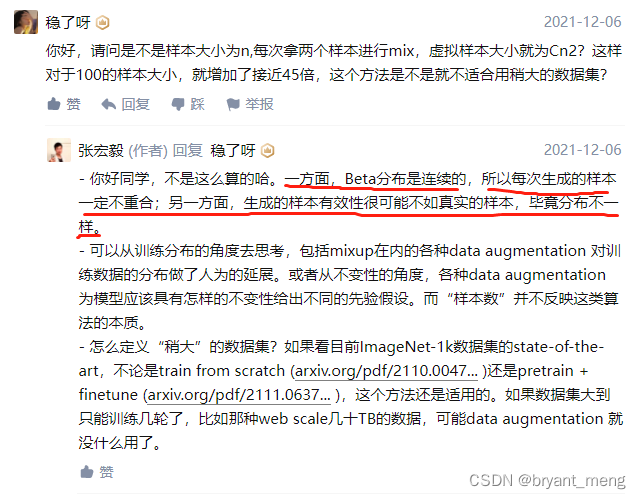
13) 《Manifold mixup: Better representations by interpolating hidden states》(ICML-2019)
简单提升点 | Flow-Mixup: 带有损坏标签的多标签医疗图像的分类(比Mixup和Maniflod Mixup更好)

本文由 在线网速测试 整理编辑,转载请注明出处。

