TCP/IP协议栈Lwip的设计与实现:之四
最后更新:2022-07-19 07:17:25 手机定位技术交流文章
参考:TCP/IP Stack Lwip的设计与实现:三长红的博客 - CSDN Blog
目录
11.协议栈接口
12.应用程序接口
12.1基本概念
12.API2的实施
13.代码统计分析
13.1代码行数
13.2目标代码大小
14.性能分析
11.协议栈接口
使用TCP/IP协议堆栈提供的服务有两种方式,要么直接使用TCP和UDP模块提供的调用功能,要么使用LWIP API,这将讨论在下一个节。
TCP和UDP模块为网络服务提供了基本的接口。该接口基于调制函数,因此,使用接口的应用程序不能连续运行。这使得应用程序难以写和代码难以理解。为了接收数据,应用程序注册了一个堆栈的回调函数,这个回调函数与特定连接有关,当一个包裹在一个链子里到达时,堆栈将调用回调函数.
更进一步,直接使用TCP和UDP模块接口的应用程序必须(至少部分)与TCP/IP堆栈相同的进程。这是因为调用函数不能通过进程边界。这既有好也有坏的一面。优点是应用程序和TCP/IP堆放在相同的进程空间中,在发送和接收数据包时,无需更改上下文,主要的缺点是应用程序不能将它纳入任何更长的运行时间计算中,由于TCP/IP处理不能与计算进行并行,这降低了通信性能。这可以通过将应用程序分成两部分来克服,一部分处理通信,一部分处理计算。处理通信的部分将在TCP/IP进程中出现,计算的主要部分成为一个独立的过程。在下一个节中,LWIP API提供了按照上述方法分解应用程序的结构化方法。
12.应用程序接口
由于BSD提供的插座API的高抽象性,它不适合在小型TCP/IP实现中使用。特别的,BSD sockets要求将要发送的数据从应用程序拷贝一份到TCP/IP协议栈的内部缓冲区。数据复制的原因是应用程序和TCP/IP堆栈通常存在于不同的保护区。大多数情况下,应用程序是一个用户过程,TCP/IP协议堆存于操作系统内核中。通过避免额外的数据复制,API性能可以大大提高[ABM95]。同样,为了数据拷贝,需要分配额外的内存,每个包使用一个双重有效的内存。
LWIP API是为LWIP设计的,并利用LWIP内部结构的理解实现高效率.LWIP API与BSD API非常相似,但它在较低的水平上运行。API不需要在应用程序和TCP/IP协议堆栈之间复制数据,因为应用程序可以直接操作内部缓冲器。
因为BSD插座很容易理解,而且已经有许多基于它编写的程序,因此,与BSD插座兼容的水平是有益的。第17部分列出了使用LWIP API重新编写的BSD插座。第15部分是LWIP API的参考手册。
12.1基本概念
从申请的角度来看,BSD插座API中的数据传输是在连续存储区进行的。这对于申请者来说更方便,因为应用程序中的数据的操作通常是在一个连续的内存块中进行的。在LWIP中使用这种机制是不有利的,因为LWIP通常在缓冲区获取数据,这里数据被分成较小的内存块。因此,在将数据传递到应用程序之前,应该将数据复制到一个连续存储区域。这不仅会浪费处理时间,而且会浪费记忆.所以,LWIP允许应用程序直接操作分隔缓冲区的数据,以避免额外的数据复制。
LWIP API使用与BSD接口API类似的抽象连接,尽管如此,它们的不同之处仍然非常值得注意;对于一个使用BSD socket API的应用程序而言,不需要实现普通文件与网络连接之间的区别,对于使用LWIP API的应用程序,它必须意识到它正在使用网络连接。
网络数据以缓冲区的形式被接收,在这里,数据被分割进小的内存块。因为很多应用希望操作连续存储区的数据,所以就存在一个来实现这一便利的函数,该函数将分片的缓冲区数据拷贝到连续的内存区。
根据数据是否通过TCP连接或作为UDP数据消息传输,发送数据的过程不同。对于TCP,最后通过将指针传递到输出函数的连续存储区.TCP/IP协议堆栈将数据分成合适的大小的包,并将其添加到传输队列中。发送UDP数据消息时,应用程序将明确指定缓冲区,并用数据填充它。当输出函数被调用时,TCP/IP协议堆将立即发送数据消息。
12.API2的实施
由于TCP/IP堆栈的进程模型,API的实现分为两个部分。如图12所示,一些API被实现为与应用程序连接的库,另一部分在TCP/IP进程中实现。两个部件使用操作系统仿真层提供的进程间通信(IPC)机制进行通信。当前的实现使用如下三个IPC机制:
1.共享内存
2.消息传递
3.信号量
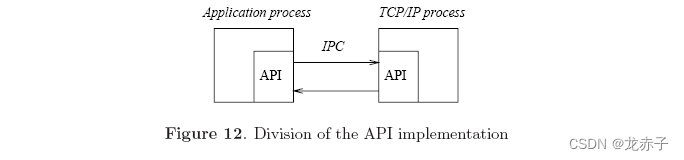
由于这些类型的IPC由操作系统层支持,它们不再需要由以下操作系统直接支持。 由于操作系统不自然支持它们,操作系统仿真层仿真实现它们
设计时通常使用的原则是尽可能多的工作是在申请过程而不是在TCP/IP进程中进行。这一点是重要的,因为所有进程都使用TCP/IP进程来通信其TCP/IP。抑制与应用程序相关的API部件的代码覆盖并不重要。这个代码的部分可以在进程之间共享,即使共享库不是由操作系统支持的,代码存储在ROM中。嵌入式系统通常有大量的ROM,而处理能力却不足。
缓冲管理被定位于API实现的库部分。缓冲区的创建、复制以及释放都在应用进程中。共享内存被用来在应用进程和TCP/IP进程间传送缓冲数据。应用程序通信中所使用的缓冲数据类型是一个抽象的pbuf数据类型。
缓冲区使用参考内存以形成与分配内存的对比,使用共享存储器进行转移。因此要能使之工作,那么,必须能够在进程之间共享参考记忆。使用LWIP的嵌入式系统所使用的操作系统通常被认为是没有实现任何形式的存储保护,因此,实现这一目标没有问题。
实现获取网络连接的功能是API的一部分,该API的这一部分在TCP/IP进程中实现。在应用程序进程中的API中运行的函数通过通过一个简单的通信协议传递消息到TCP/IP进程中的API。该消息包括要完成的操作类型和操作所需的任何参数。该操作由API在TCP/IP进程中实现,返回值通过消息传输发送到应用程序进程中。
13.代码统计分析
本节分析了LWIP代码,包括目标代码大小和原始代码的行。 该代码编译了两个架构处理器:
1.Intel Pentium III处理器,今后作为Intel x86处理器提及。使用gcc 2.95.2在FreeBSD4.1下编译,编译优化选项是打开的。
2.6502处理器[Nab, Zak83].使用cc65 2.5.[VB]编译,编译优化选项也开放。
英特尔x86有7个32位存储器,使用32位指针。 6502主要用于嵌入式系统,有8位存储器和2个8位索引存储器,以及16位指针。
13.1代码行数
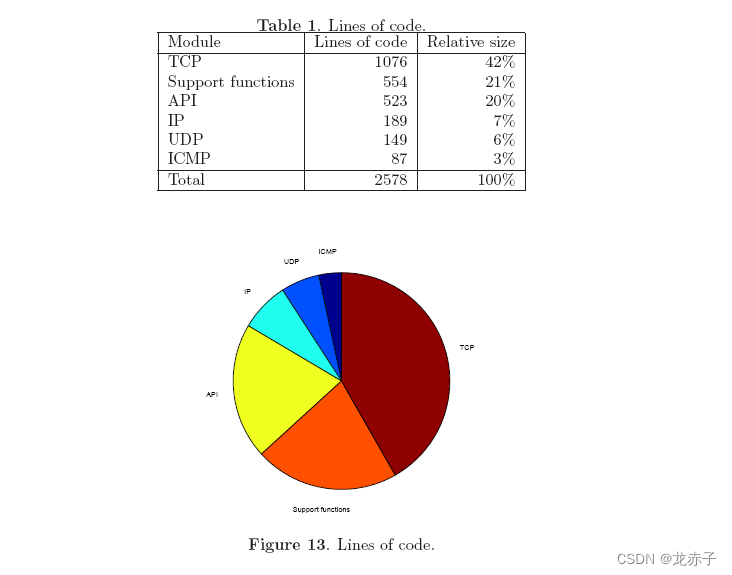
表1概述了LWIP源代码的行,图13显示它们之间的比例关系。Support functions项目包括缓冲和内存管理的函数以及计算Internet校验和的函数。采用通用C算法实现检验和函数,当实际配置执行时,请用处理器相关实现取代它。API项包括与应用程序关联的API和与TCP/IP堆栈关联的API。本分析不包括操作系统仿真层。因为它的大小随下层的操作系统的不同而有很大的变化,因此, 没有 必要 进行 比较 。
由于目的是进行比较,所以所有的注视和空白行都从原文件删除了。同样,该比较中也没有包括头文件。我们可以看到,TCP远远大于其他协议的实现,API和支持函数和起来的大小与TCP相当。
13.2目标代码大小
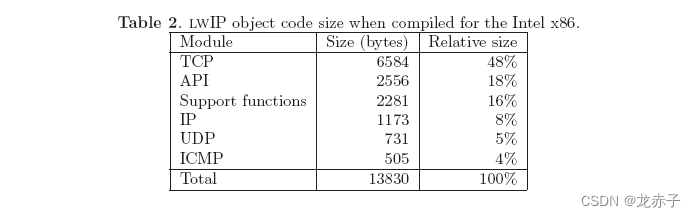
表2总结了目标代码的大小,与Intel x86编译器相比。图14显示它们的相对比例关系。我们 可以 看到, 项目 的 顺序 与 表 1 不同 。这里,API比支持函数项目大,虽然支持函数项目有更多的代码。我们还可以看到,TCP占编译代码的48%,仅占源代码的42%。检查TCP模块的编译输出显示了这一现象的可能原因。TCP模块包含大量的非关联标记,这扩大了汇编代码,因此,目标代码的大小增加了。因为每个函数中的许多指针都重复地被关联两次或三次,这可以通过修改源代码来优化,仅在关联并置于一个局部变量后才能达到这些点。同时减少编译代码的大小,更多的RAM也被用来作为本地变量空间。这些RAM被分配到协议堆栈中。
表3显示在6502编译时目标代码的大小,图14显示比例关系。我们可以看到,TCP、API和支持功能在Intel x86下几乎是目标代码的两倍,IP、UDP和ICMP的大小相似。我们也可以看到支持函数项目比API大,与表2相反。然而,API和支持函数之间的大小差异略小。
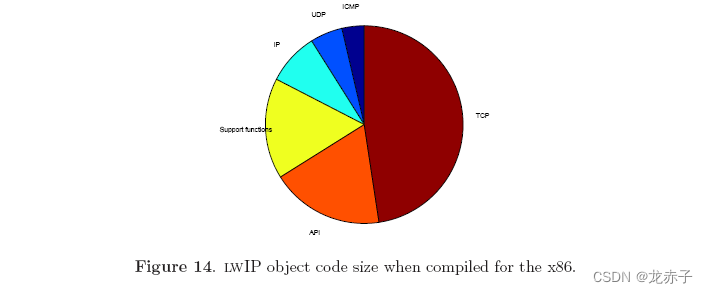
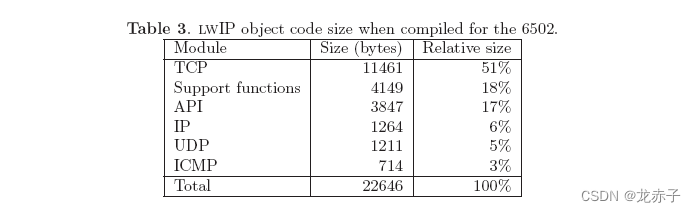
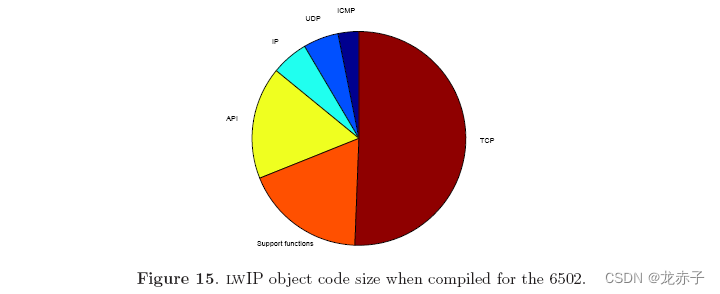
TCP模块大小的增加是由于6502 Gene不支持32位整数,所以每个32位操作被编译器扩展到编译代码的一系列行。 TCP序列数是一个32位整数,而TCP模块有大量的序列数计算。
这里可以将TCP大小与其他TCP模块在TCP/IP堆栈中比较,例如,FreeBSD 4.1上的流行的BSD TCP/IP堆栈以及源自Linux 2.2.10独立的TCP/IP堆栈。两者都基于Intel x86,并使用gcc编译,优化选项也开放。LWIP中TCP的实现大小接近6600字节,FreeBSD4.在1中实现TCP的目标代码大小约为27,00字节,是LWIP的4倍。Linux 2.2.大于10,为39000字节,它可能是六倍的LWIP。LWIP和其他两个实现的大小巨大差异是由于FreeBSD和Linux的实现,这些实现包含了更多的TCP功能,如SACK[MMFR96],以及一些BSD接口API的实现。
之所以不对IP部分的实现进行比较是因为在FreeBSD和Linux的IP实现中包含了更多的特性。举个例子,FreeBSD和Linux在IP实现中都支持防火墙和通道,另外,他们的实现支持动态路由表,这不是在LWIP中实现的。
LWIP API可能是LWIP的六分之一,因为LWIP可以在没有API的情况下使用,而这个部分可以忽略,也就是在LWIP配置在一个只有一个小代码存储系统时不能忽略。
14.性能分析
本文没有对LWIP的性能进行正式测试,无论是在RAM使用还是代码效率方面。这 已 在 今后 的 工作 中 加以 考虑 。尽管如此,一个简单的测试仍然进行。结果表明,运行简单的HTTP/1.0服务LWIP可以满足至少10个同时的网页请求,RAM使用量少于4KB。在那些测试中,只考虑协议、缓冲系统和应用程序使用的内存,因此,该设备驱动器使用的内存应该添加到上面的数据,这意味着RAM不仅比实际使用的4KB小。
TCP/IP协议 Stack Lwip的设计与实现:五年的博客 - CSDN Blog
本文由 在线网速测试 整理编辑,转载请注明出处。

