torchvision.datasets.ImageFolder前的数据整理及使用方法
- 测试:5张照片要分类
- 火车:训练车组图片,总共100件
- Train Labels.csv:培训重点放在每个图片的相应类别上
- train_valid:保存所有图片,即100
- 有效:保存验证集合图像,即80
- 火车:保存920幅图片的训练集
- 根:存储的图片的根目录,即位于其他文件夹的目录的顶层目录。在上面的例子中,训练集合的根目录是
./train_valid_test/train - transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片
- target_transform:对图片类别进行预处理的操作,输入为 target,输出对其的转换。如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…
- 负载器:指示数据集负载模式,通常是默认的
- self.classes:用一个 list 保存类别名称
- self.class_to_idx:与类相符的索引,与无转换返回的目标相符
- self.imgs:保存(img-path, class) tuple的 list,与我们自定义 Dataset类的 __getitem__返回值类似
最后更新:2022-07-22 02:32:54 手机定位技术交流文章
通常在一个完整的神经网络训练流程中,我们常常需要构建Dataset和Dataloader用于后续模型训练时的数据读取,一般我们自己定义一个Dataset类,重写
__geiitem__和__len__函数来构建Dataset。然而对于简单图像分类任务而言,无需自己定义Dataset类,调用torchvision.datasets.ImageFolder函数可以建立自己的数据集, 非常方便.
这个守则指李先生的“实践深入学习”
一个.将数据集安排成函数特有格式
由于它被称为API,所以数据集必须按照API要求组织,torchvision.datasets.ImageFolder需要以下列方式组织数据集:
其中dog和cat表示图片的标签。在根目录下,我们需要将每一个种类都创建一个文件夹,并在该文件夹下存入该种类对应的图片。如果我们的图片分为apple、banana和orange三个类别,然后我们需要创建三个文件夹,名称与三个标签相符,文件夹在标签下存储相应的图像。
然而,有时我们得的是数据集,这些数据集不是完全在这个格式,然后我们需要组织这些数据集,这很耗时。这里我将拿一个数据集的集合作为一个例子,并解释如何以程序的形式组织数据集。其他格式的数据集也可以参考。
1.1原始数据集格式
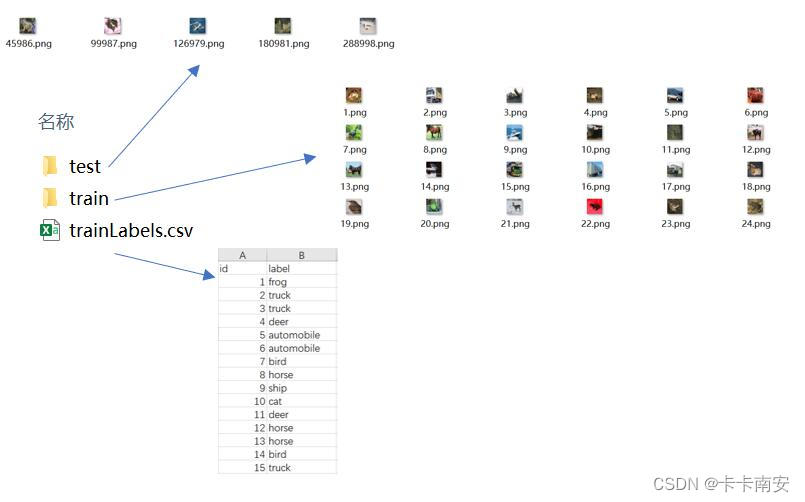
1.2 整理数据集
首先,我们使用以下函数读取CSV文件中的标签,它返回一个字典,该字典没有扩展到它的标签的文件名的一部分。
接下来,我们定义reorg_train_valid将验证集与原始训练集分开的函数。该函数的参数valid_ratio这是验证的样品数量与最初训练的样品数量的比率。 更具体地说,让 n 等于最小样品类别的图像数目,而r是比率。确保每个类型的图像的数目是相同的,验证设置将分隔每个类别的最大(nr,1)图像。因此,最后验证集合图像的总数是最大(nr,1)乘以类别数
在这种情况下,该类图像的最小数目为85,比例为0.1,因此最终验证集的数目为85×0.1 × 10 = 80
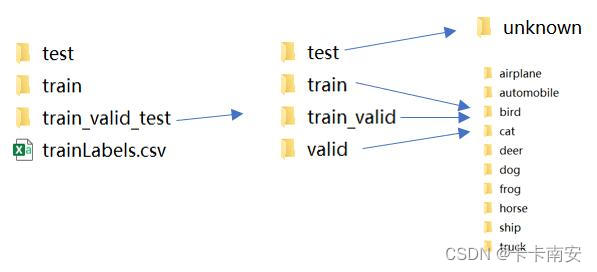
函数reorg_train_valid会生成一个大文件夹train_valid_test其中分别有三个文件夹:
每个文件夹包含每个类型的相应的文件夹。
下面的reorg_test函数用于在预测时组织测试集的可读性。
测试集的图像将被保存在名称中unknown的文件夹下。
最后,我们使用一个函数来调用先前定义的函数read_csv_labels、reorg_train_valid和reorg_test。
运行后,在根目录下将生成一个名称train_valid_test的文件夹,里面包含test、train、train_valid和valid四个文件夹。
二. 调用torchvision.datasets.ImageFolder构造Dataset
torchvision.datasets.ImageFolder(root,transform,target_transform,loader)
此外,API具有下列成员变量:
以下为构建训练集、验证集和测试集的数据集:
在训练期间,我们需要指定上面定义的所有图像扩展操作。在过参数调整过程中使用验证集进行模型评估时,不应引入随机性来放大图像. 在最终预测之前,我们以培训模式为基础进行培训,结合培训和核查,充分利用所有标记数据.
在构建数据集之后,您可以继续构建数据负载器:
最后拿一下数据载入器,去跳舞吧~
本文由 在线网速测试 整理编辑,转载请注明出处。

